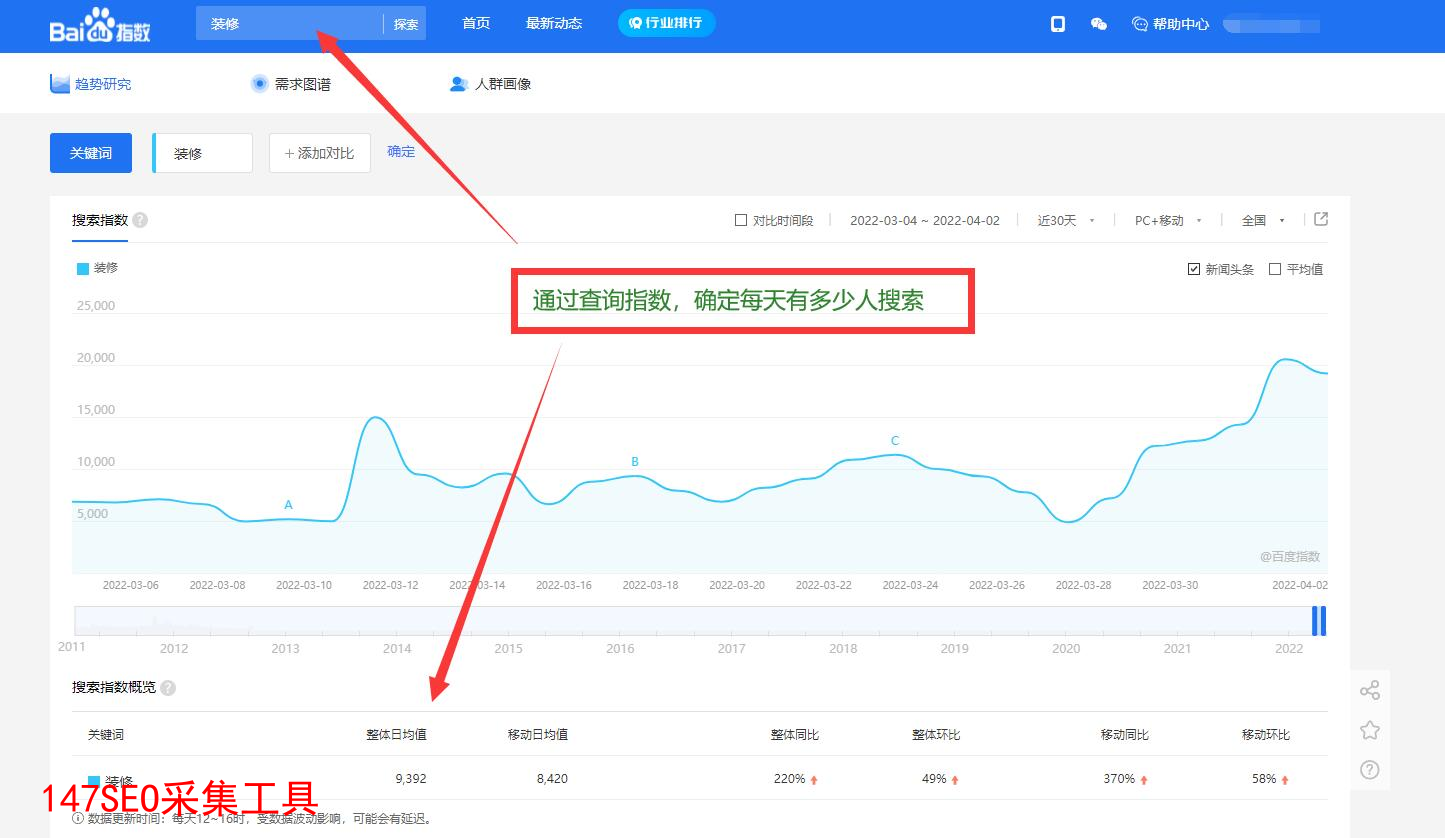
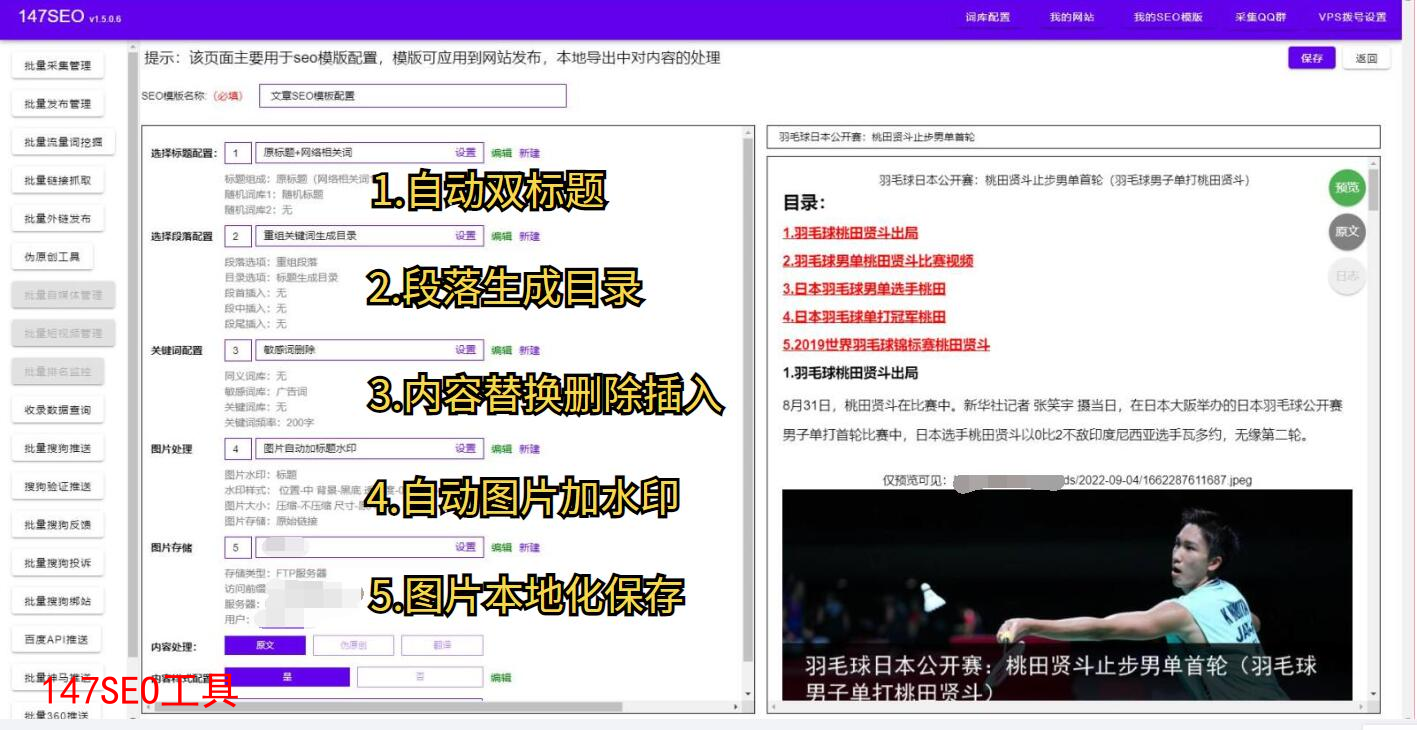
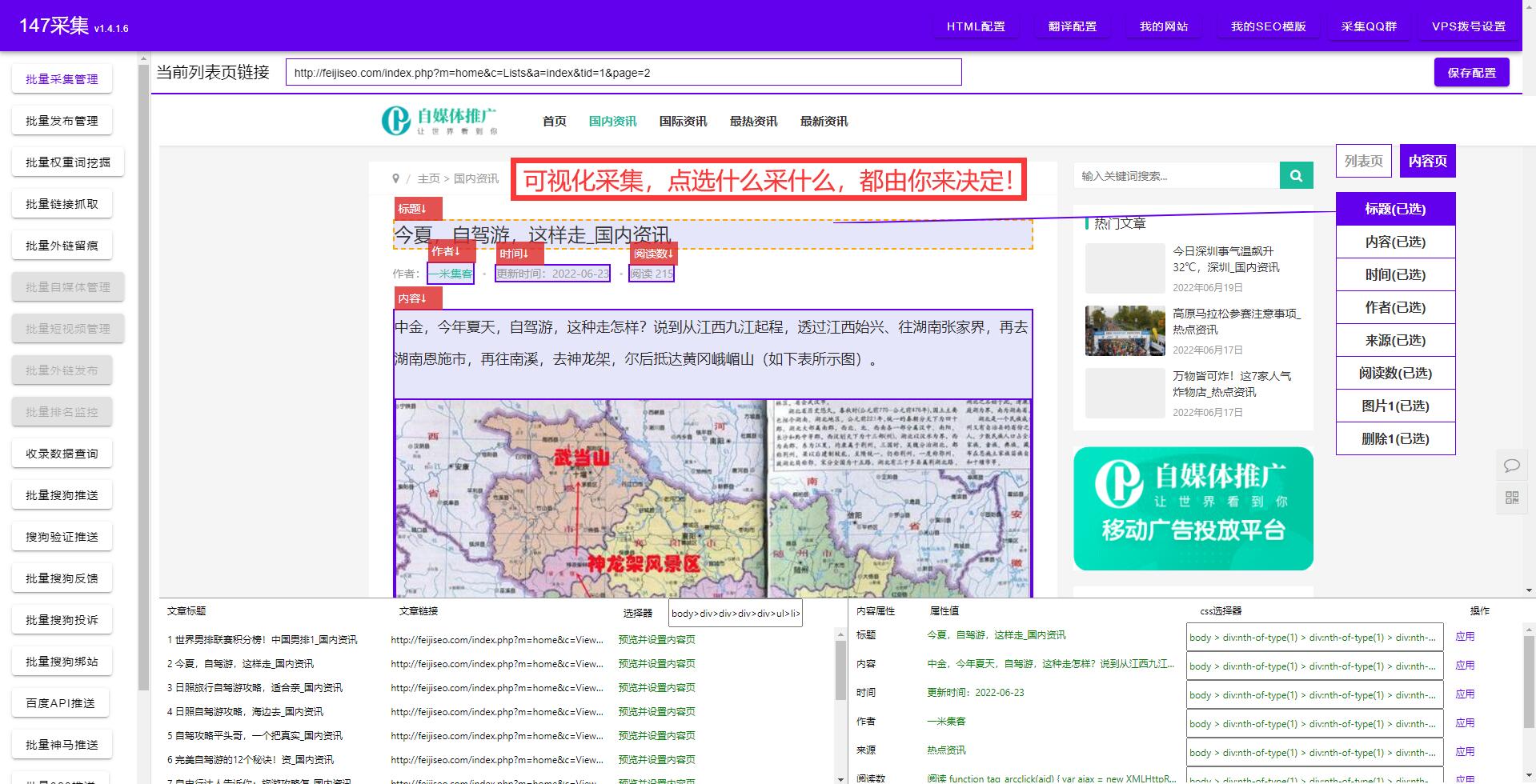
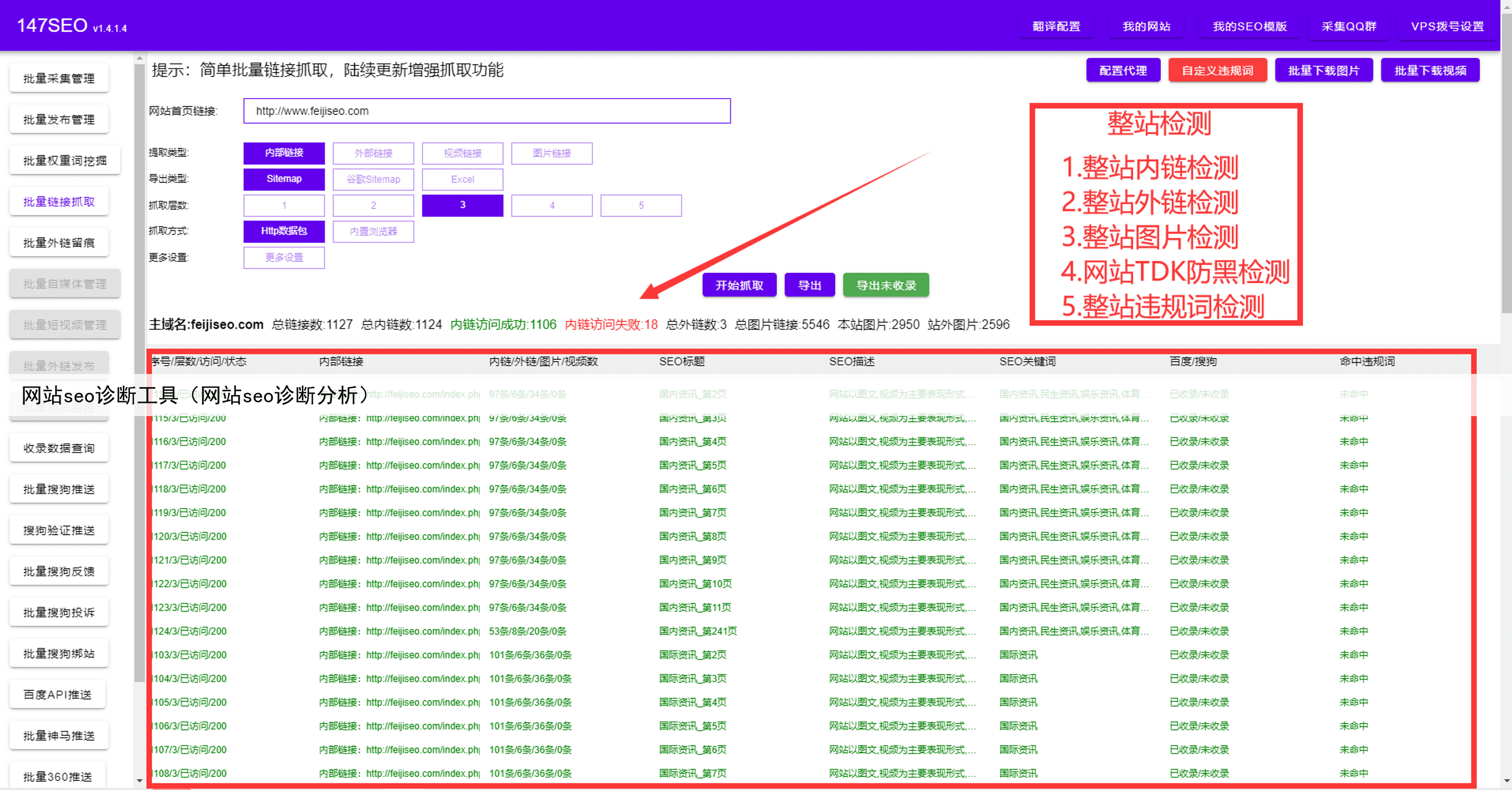
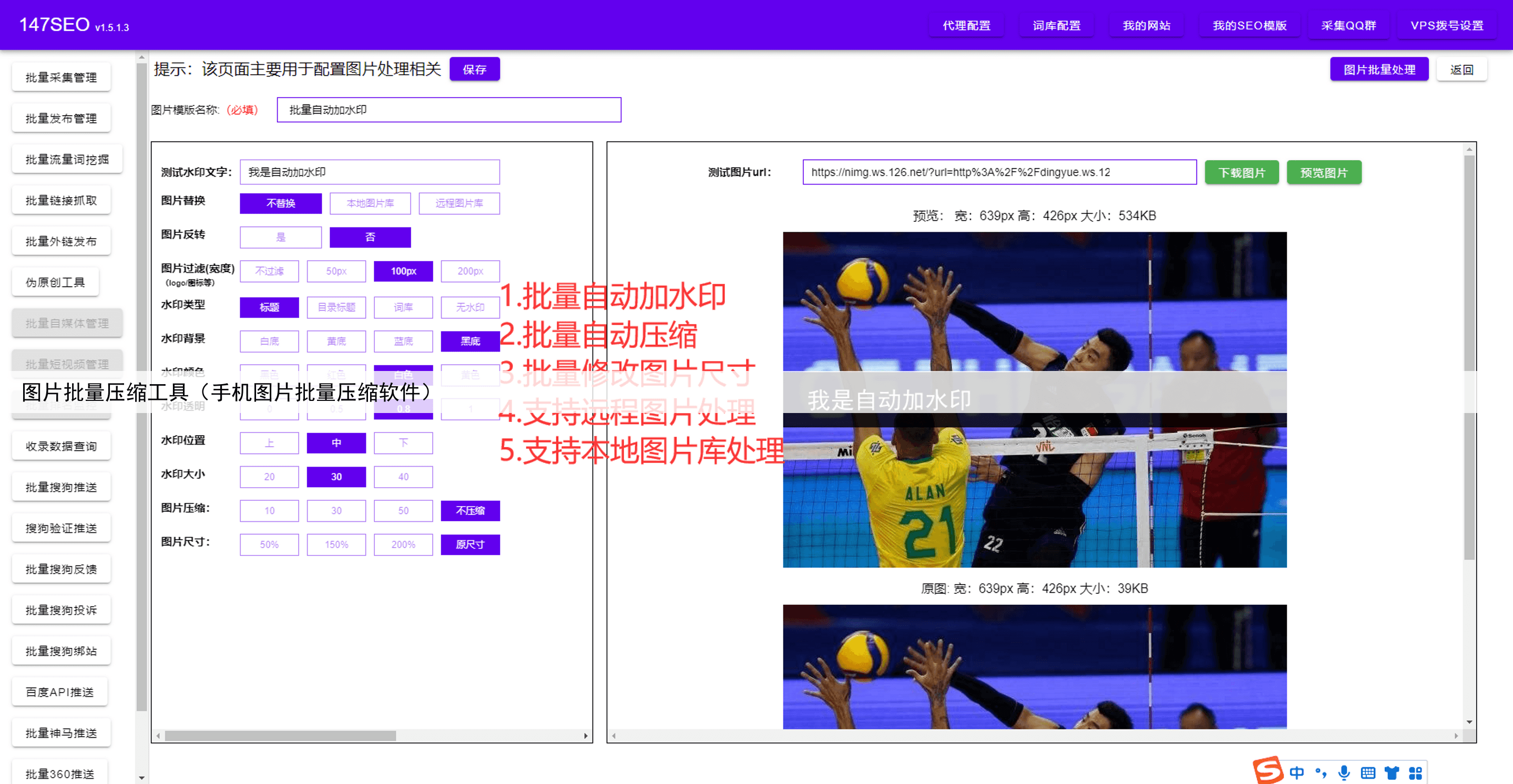
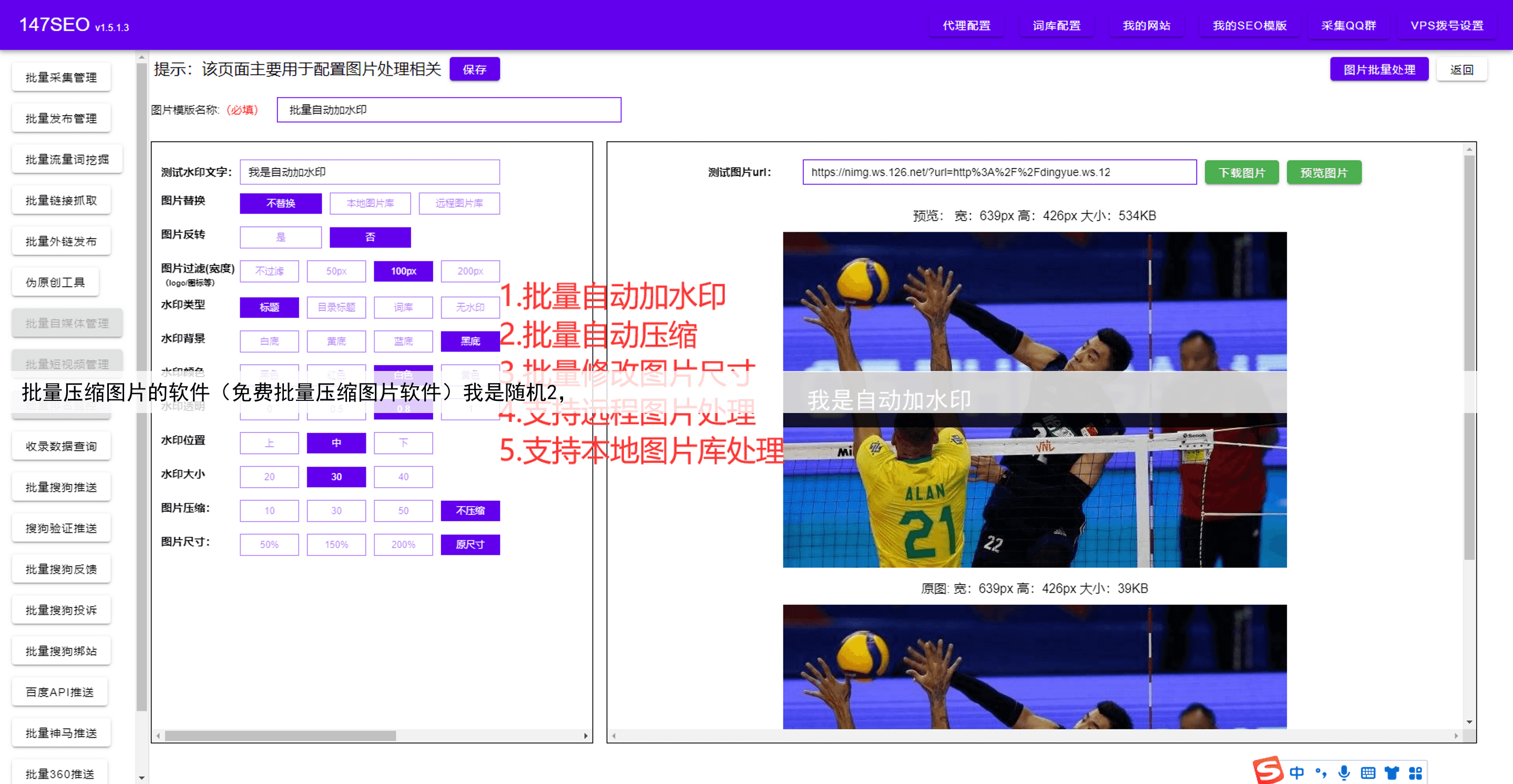
摘要:随着社会不停地进步。互联网已经完美的融入了日常生活,大家也越来越意识到数据的重要性,不管是同行的数据,还是自己的数据。今天小编就给大家来盘点一下好用的数据采集器软件有哪些。只需要点几下鼠标就能轻松采集数据,不管是导出excel还是自动发布到网站都支持。取代手动复制粘贴,提高效率,节省下更多时间。彻底解决没有数据的问题,同时也告别了手动复制粘贴的痛苦。详细参考图片一、二、三、四!
目录:
1.python爬取网页文字
2.python 爬取网页内容
3.python怎样爬取网页一篇文章
4.python爬取文章内容
5.python爬取csdn所有文章
6.如何爬取网页的文本
7.python爬虫爬取网页数据
8.python 爬取网页文件
9.python爬取页面文档
10.如何利用python爬取网页内容
1.python爬取网页文字
随着社会不停地进步互联网已经完美的融入了日常生活,大家也越来越意识到数据的重要性,不管是同行的数据,还是自己的数据今天小编就给大家来盘点一下好用的数据采集器软件有哪些只需要点几下鼠标就能轻松采集数据,不管是导出excel还是自动发布到网站都支持。
2.python 爬取网页内容
取代手动复制粘贴,提高效率,节省下更多时间彻底解决没有数据的问题,同时也告别了手动复制粘贴的痛苦详细参考图片一、二、三、四!

3.python怎样爬取网页一篇文章
企业人员通过爬取动态网页数据分析客户行为拓展新业务,同时还能通过数据更清楚竞争对手,分析竞争对手并超越竞争对手网站人员实现自动采集,定时发布,自动SEO优化让你的网站瞬间拥有强大的内容支撑,快速提升流量与人气。
4.python爬取文章内容
搜索引擎蜘蛛是我们网站被百度或者其他搜索引擎收录的技术媒介,也就是说搜索引擎会通过蜘蛛来抓取我们的网站。不错的内容就会给予相应的搜索排名了即关键词排名。

5.python爬取csdn所有文章
搜索引擎蜘蛛的概念搜索引擎蜘蛛就像一个人在一个杂乱无章的图书馆里浏览所有的书籍,然后把一个卡片目录放在一起,这样任何访问图书馆的人都可以快速而轻松地找到他们需要的信息为了帮助按主题对图书馆的图书进行分类和排序,组织者将阅读每本书的标题、摘要和一些内部文本,以了解它是关于什么的。
6.如何爬取网页的文本
然而,与图书馆不同的是,互联网并不是由一大堆书组成的,这使得人们很难判断所有必要的信息是否都被正确地编入了索引,或者是否有大量的信息被忽视了为了找到互联网提供的所有相关信息,搜索引擎蜘蛛会从一组已知的网页开始,然后跟踪从这些网页到其他网页的超链接。
7.python爬虫爬取网页数据
这就是为什么做外链可以让蜘蛛尽快发现新的网站的原因了

8.python 爬取网页文件
如何让网站更好的被搜索引擎蜘蛛抓取?网站如果想快速被百度或者其他搜索引擎收录,那么需要搜索引擎蜘蛛来抓取那么如果想吸引搜索引擎蜘蛛来爬取我们的网站,那么就需要高质量的内容来做支撑了如果我们的网站不被百度和其他搜索引擎收录,那么多半是优化做的有问题。
9.python爬取页面文档
搜索引擎抓取我们的网站并不是通过蜘蛛抓取网页信息以后存储起来,而是变成网页快照的形式用户在搜索引擎搜索相关的关键词的时候就会调用最匹配的网页快照信息给予匹配,这也就是关键词排名的原理了百度网站快照抓取的样式,我们的网页只有被谷歌纳入快照了才有机会获得相应的排名。
10.如何利用python爬取网页内容
前面的内容中介绍了“什么是搜索引擎蜘蛛?”,这篇内容要详细的带大家了解网页快照的概念以及如何使用网页快照是什么?搜索引擎蜘蛛通过链接的爬取来收集网站的网页信息,接着汇总、分类用户在搜索引擎搜索相关的关键词的时候就会调用最匹配的网页快照信息给予最匹配的网页信息。

实现这个的方式就是通过蜘蛛的网页爬抓形成网站快照,存储在自己的服务器缓存里。也就是说网页快照是搜索引擎对于抓取网页的备份,英文名称为:Web Cache。网页快照的基础概念了解一下就好了。