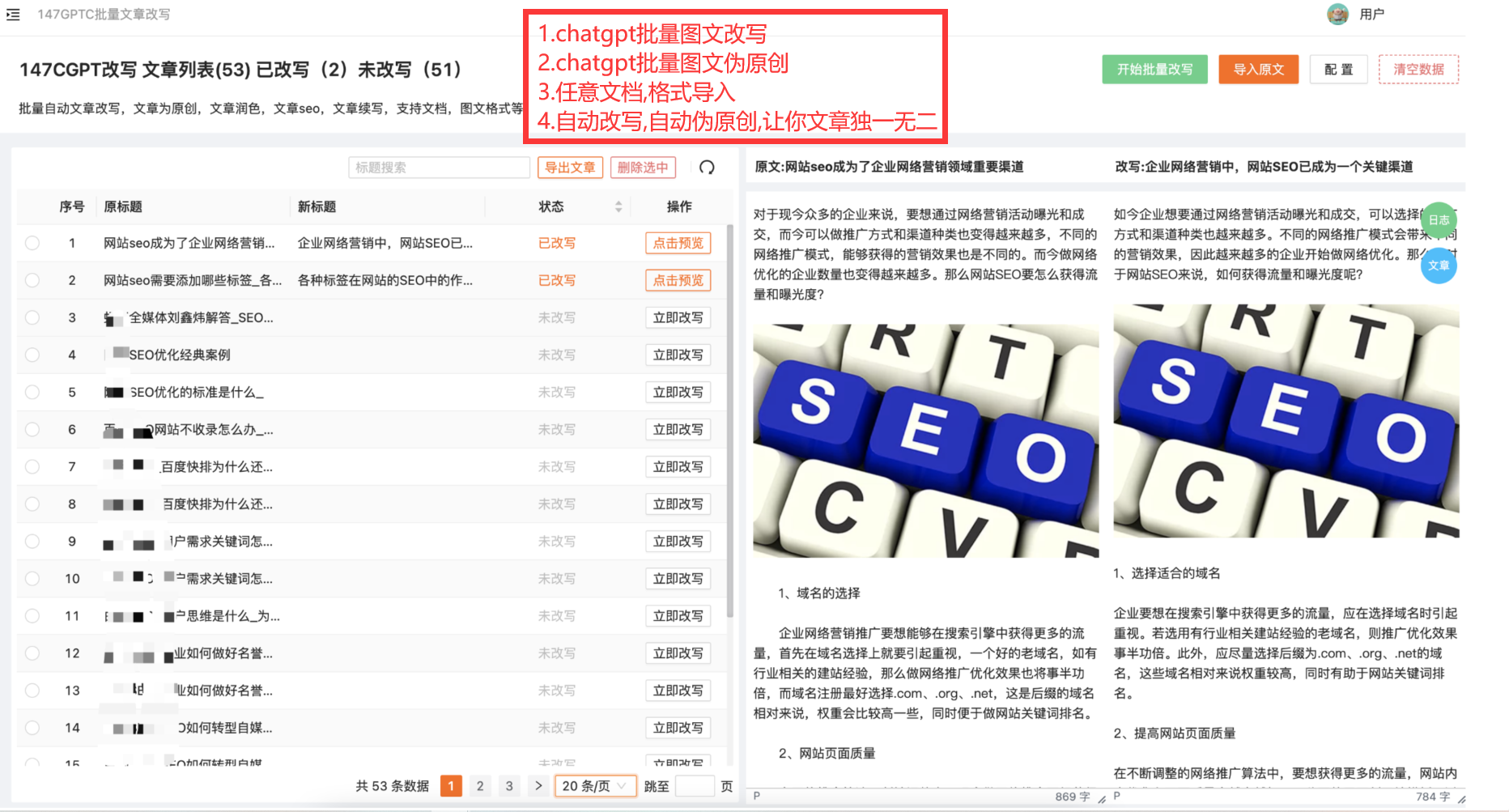
摘要:本文介绍了使用Python编写网页爬虫的方法和技巧,包括URL请求、网页解析、数据提取和存储等内容。
Python爬取网页的方法总结

关键词:Python,爬虫,网页爬取,数据采集
摘要:本文介绍了使用Python编写网页爬虫的方法和技巧,包括URL请求、网页解析、数据提取和存储等内容。
一、引言

随着互联网的发展,大量的数据在网页上得到了展示。为了有效地利用这些数据,提供有用的信息和洞察力,网页爬虫应运而生。Python作为一种简单易用且功能强大的编程语言,成为了众多开发者首选的工具之一。本文将介绍Python爬取网页的方法和技巧,帮助读者快速入门并解决实际问题。
二、URL请求
爬虫的第一步是向目标网页发送HTTP请求,获取网页的源代码。Python提供了多种库来实现这个过程,比较常用的有urllib、requests等。可以使用这些库中的函数来发送GET或POST请求,并获取服务器返回的数据。在请求过程中,可以设置请求头、代理服务器、超时时间等参数,以便更好地模拟浏览器行为,提高爬虫的稳定性和安全性。

三、网页解析
获取到网页的源代码后,下一步是进行网页解析。解析的目的是从网页中提取出所需的数据,通常使用HTML解析库进行处理。Python中常用的HTML解析库有BeautifulSoup、lxml等。这些库可以帮助我们快速定位和提取HTML元素,从而获得所需的数据。此外,还可以使用XPath、正则表达式等技术进行更高级的模式匹配和数据抽取。
四、数据提取

数据提取是爬虫的核心部分。在解析的基础上,可以根据所需数据的具体位置和格式,使用相应的方法和技巧进行数据的提取和清洗。可以提取的数据形式多种多样,例如文本、图片、链接等。根据实际需求,可以使用Python中的字符串处理函数、正则表达式、XPath等进行数据的进一步处理和转换。
五、数据存储
获取到所需数据后,需要对其进行存储。Python支持多种数据存储方式,包括文本文件、Excel表格、数据库等。可以选择适合自己需求的存储方式,并使用相应的库和方法进行数据的保存和管理。此外,还可以使用数据可视化工具对数据进行展示和分析,提高数据的易读性和使用价值。
六、总结
本文介绍了使用Python进行网页爬取的方法和技巧,包括URL请求、网页解析、数据提取和存储等内容。通过学习和掌握这些技术,可以更好地利用Python爬虫来获取和处理网页数据,为数据分析和应用开发提供有效支持。希望本文对读者在学习和应用中有所帮助。
七、参考文献
-Python官方文档:https://www.python.org -BeautifulSoup文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc/ -lxml文档:https://lxml.de -requests文档:https://docs.python-requests.org