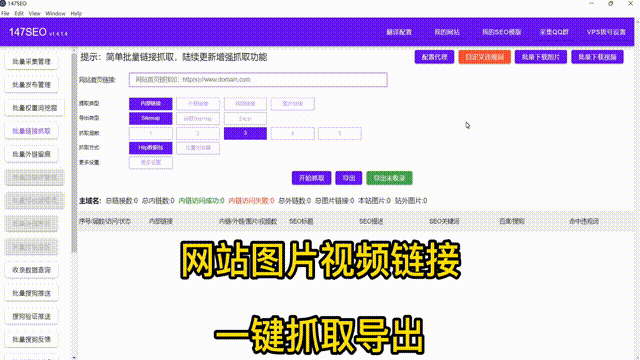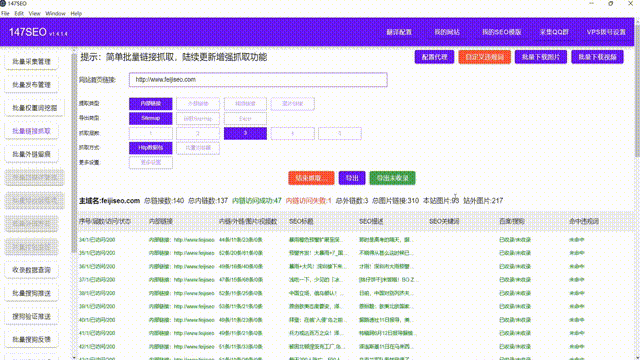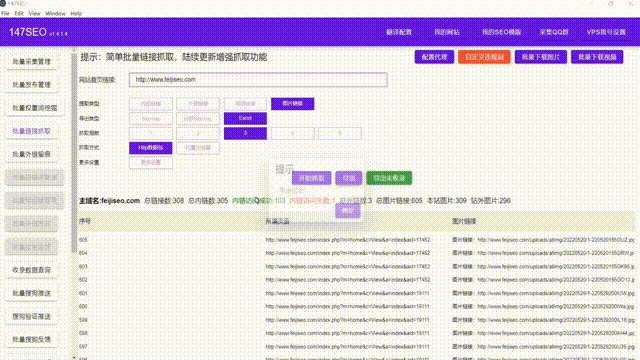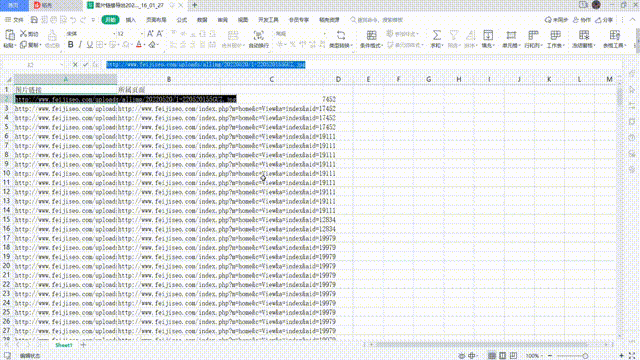
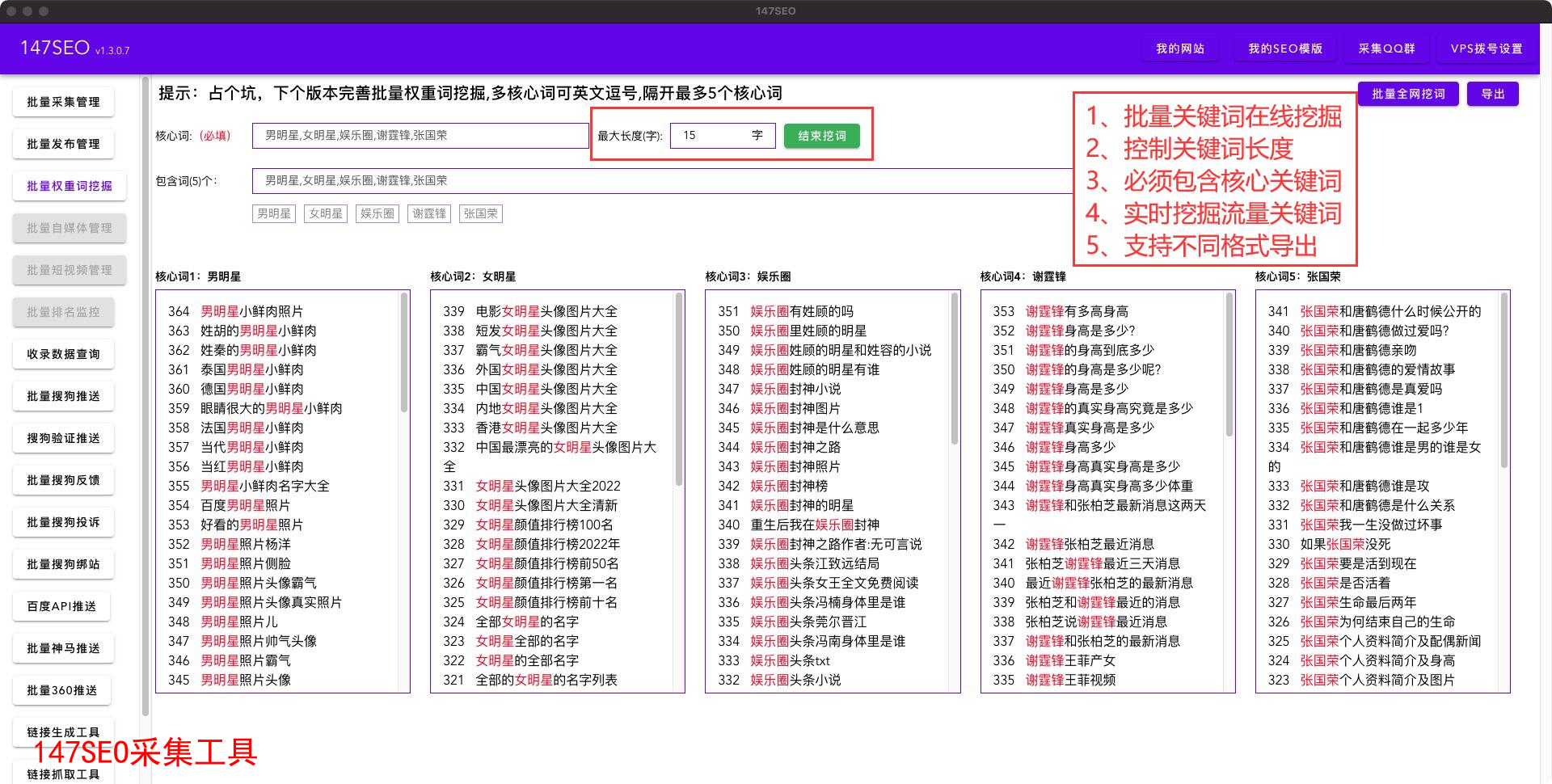
摘要:本文总结了使用爬虫技术获取网页数据的方法和注意事项,并探讨了其在不同领域的应用。
爬虫技术是指通过编写程序模拟人的行为,自动访问互联网上的页面并提取相关数据。在本文中,我们将重点讨论用爬虫技术爬取网页数据的方法和经验总结。

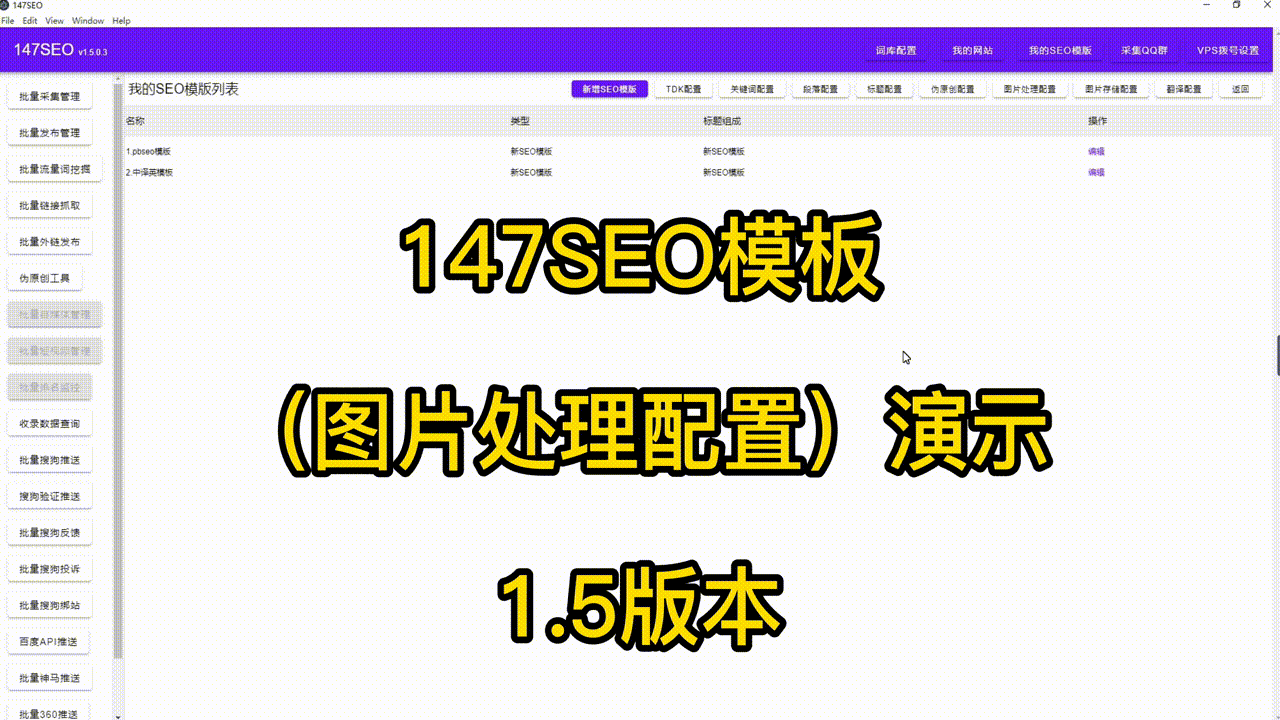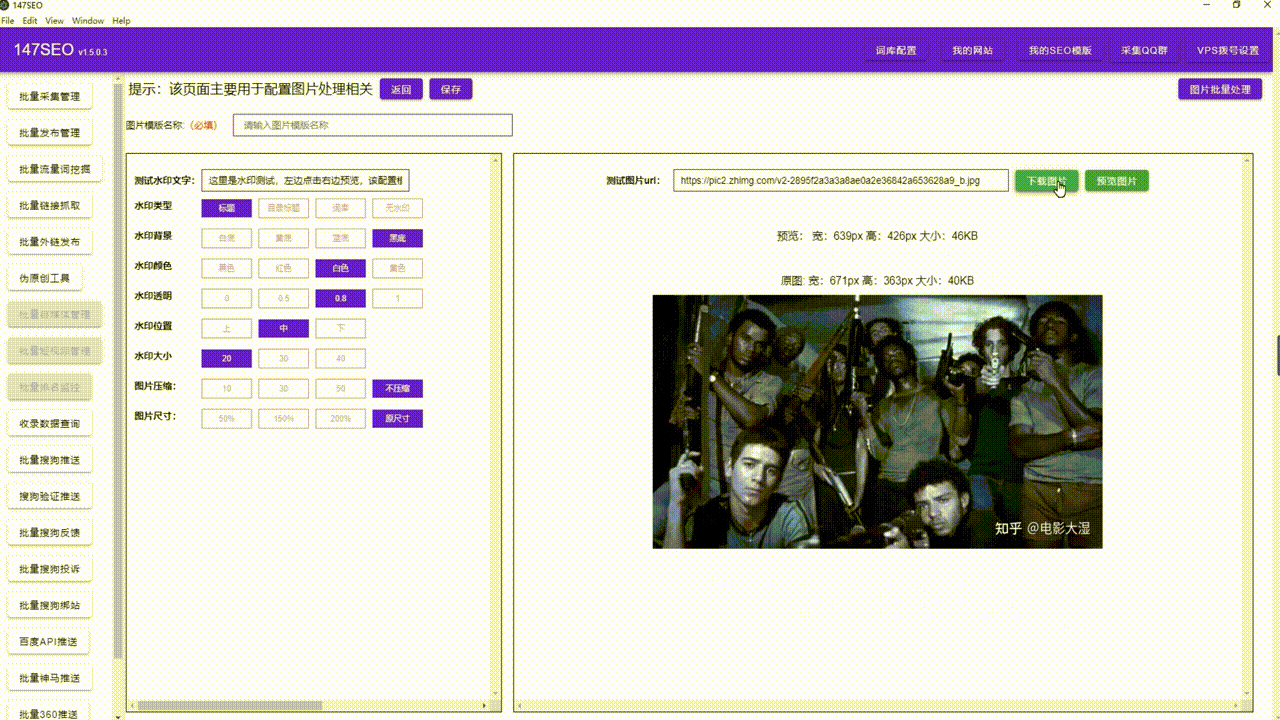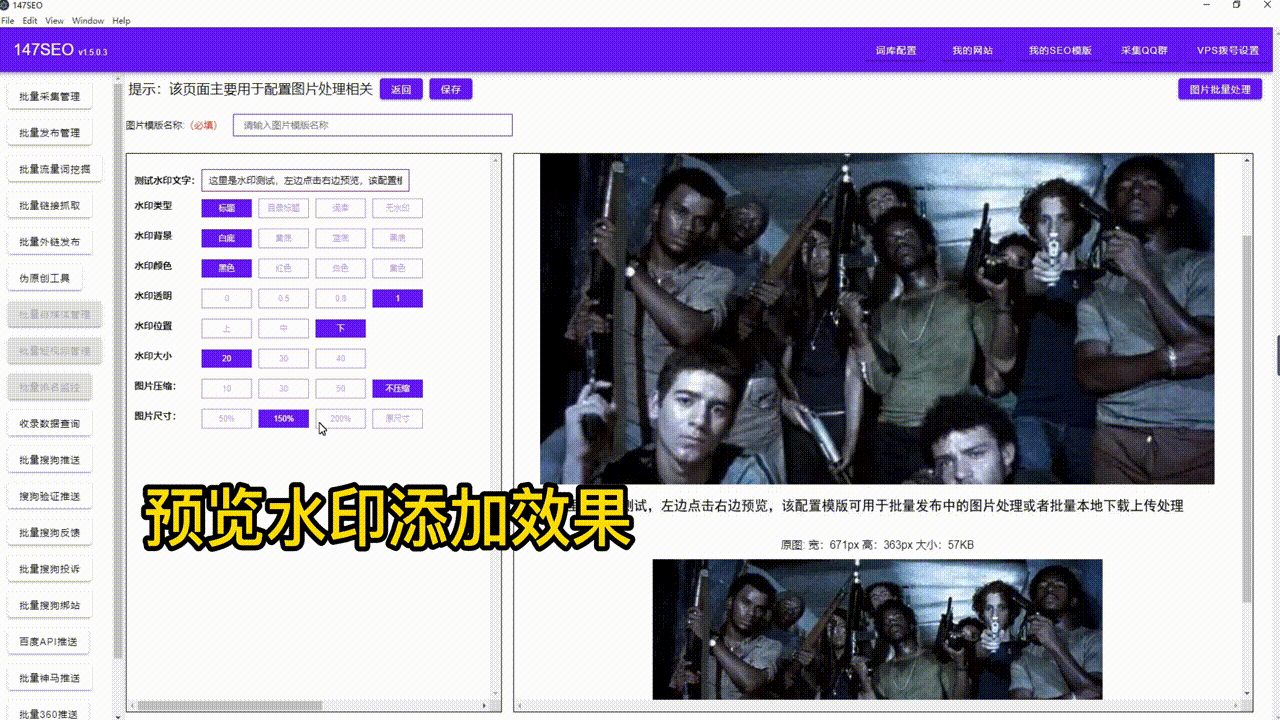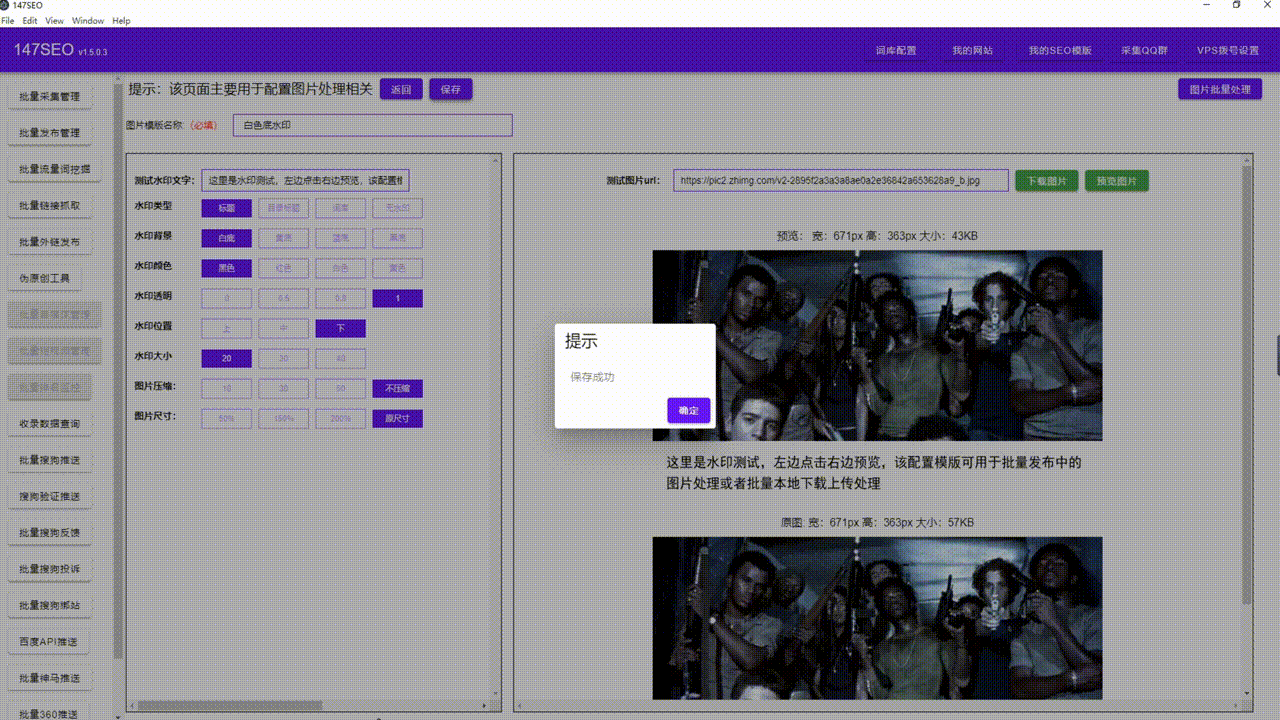
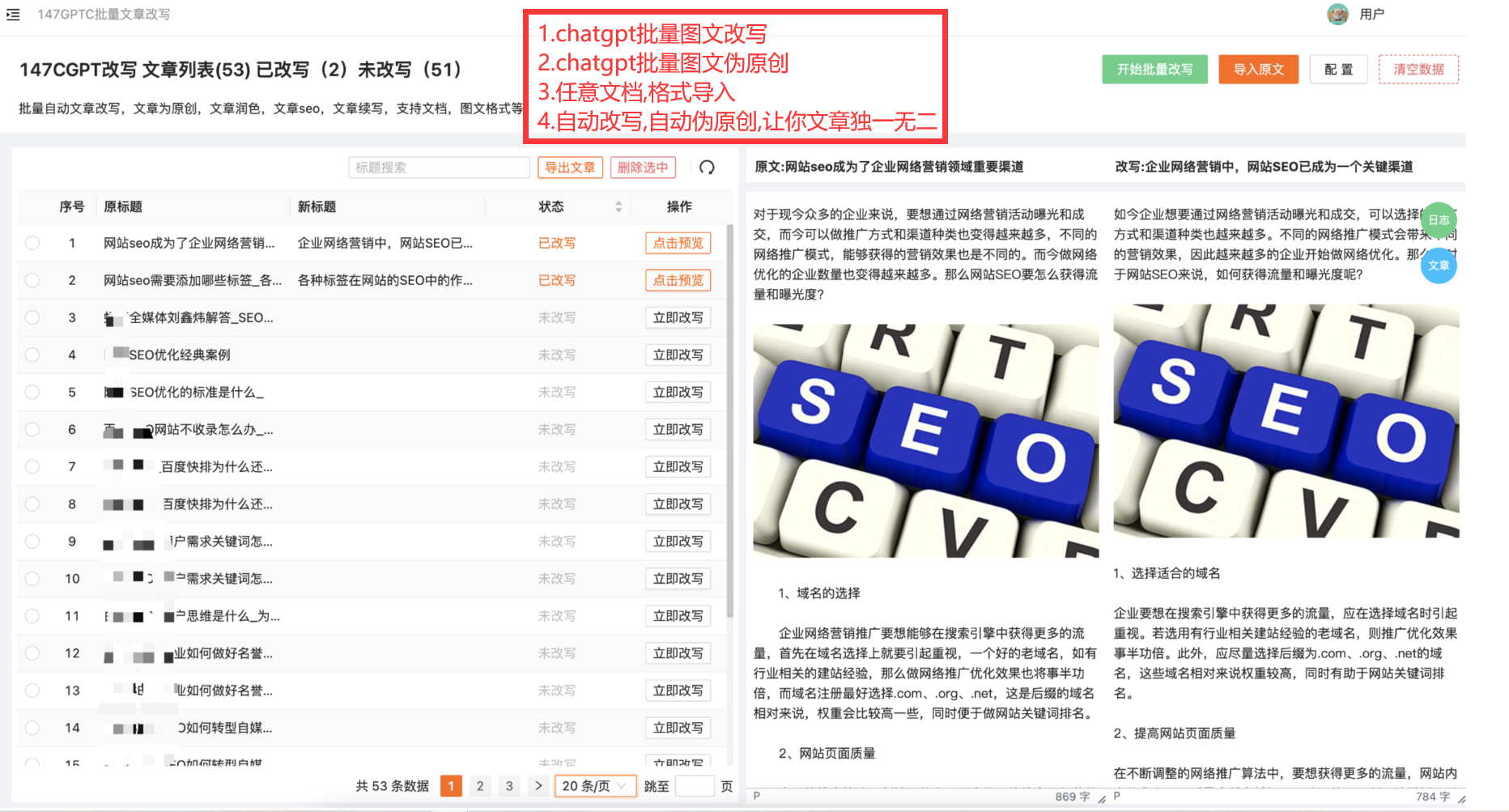
首先,要使用爬虫获取网页数据,需要掌握基本的编程语言知识,特别是对于Python这样的通用编程语言。Python提供了许多强大的库和框架,如BeautifulSoup和Scrapy,用于解析和提取网页数据。掌握这些工具的使用对于快速开发高效的爬虫程序至关重要。
其次,需要了解网页的结构和常见的网页爬取策略。大多数网页使用HTML标记语言进行编写,因此我们需要了解HTML的常见标签和属性,以便正确地定位和提取所需的数据。此外,了解常见的爬虫技术限制,如反爬虫机制、验证码和IP封锁,有助于我们设计更鲁棒和可靠的爬虫程序。
在使用爬虫技术爬取网页数据时,我们还应该遵守一些伦理和法律规定。首先,我们应该尊重网站的爬虫政策,遵守robots.txt协议,避免对网站造成不必要的压力。其次,我们不应该滥用爬虫技术,如用于非法目的、恶意攻击或侵犯他人隐私。爬虫技术应该合法、道德地使用。

爬虫技术在许多领域都有广泛的应用。在互联网搜索领域,搜索引擎通过爬虫技术获取和索引网页数据,为用户提供快速准确的搜索结果。在金融领域,爬虫技术可以用于自动抓取gupiao行情、caijing新闻等相关数据,为投资人提供参考。在电商领域,爬虫技术可以用于价格比较和竞争对手分析,帮助商家制定营销策略。在科学研究领域,爬虫技术可以用于获取学术论文和研究数据,加快科研进展。
总之,爬虫技术是一种强大的工具,可以用于获取网页数据,并在各个领域发挥重要作用。要使用爬虫技术获取网页数据,我们需要掌握相关的编程语言和工具,了解网页结构和爬虫策略,并遵守法律和伦理规定。随着互联网的不断发展,爬虫技术的应用前景将更加广阔。