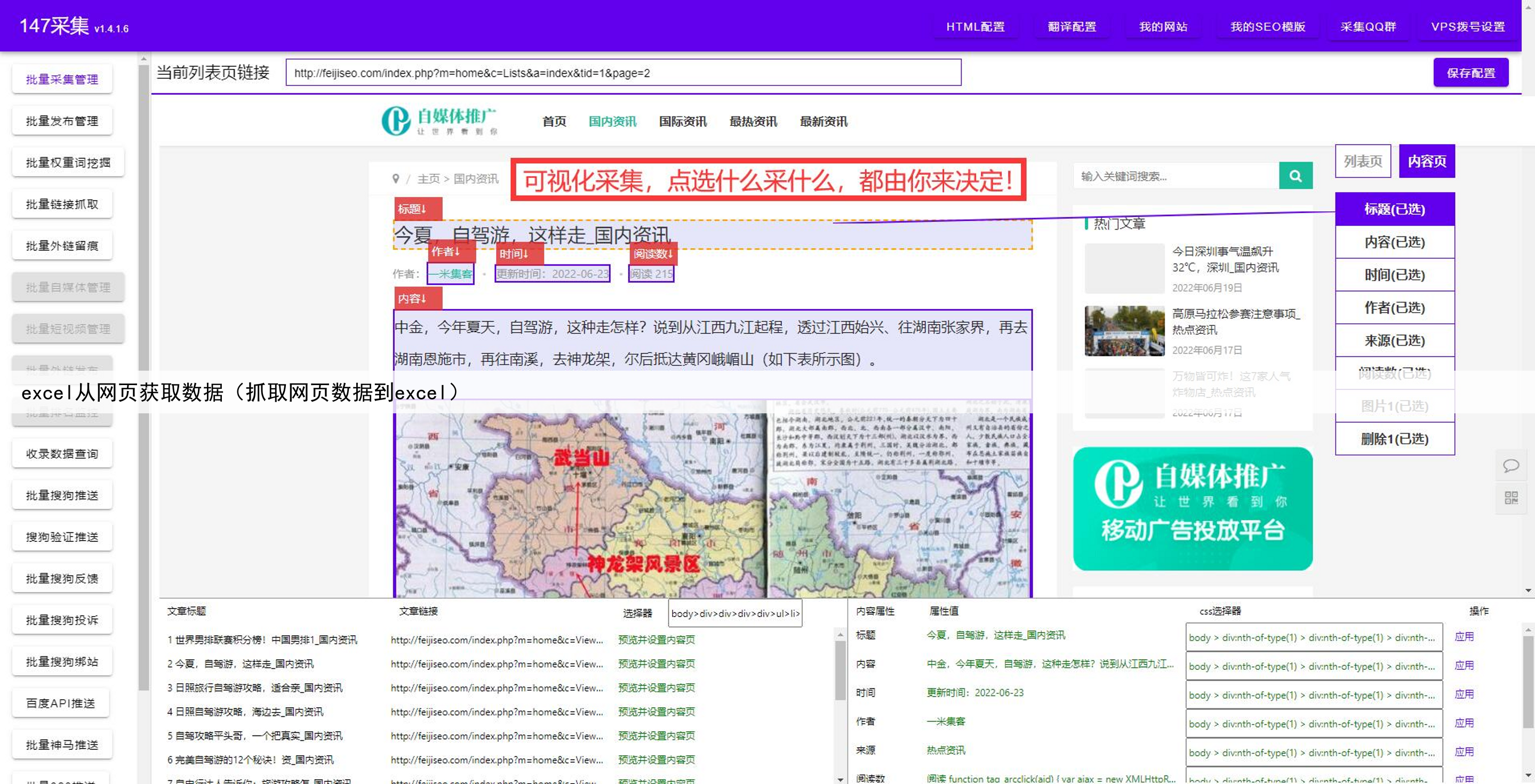
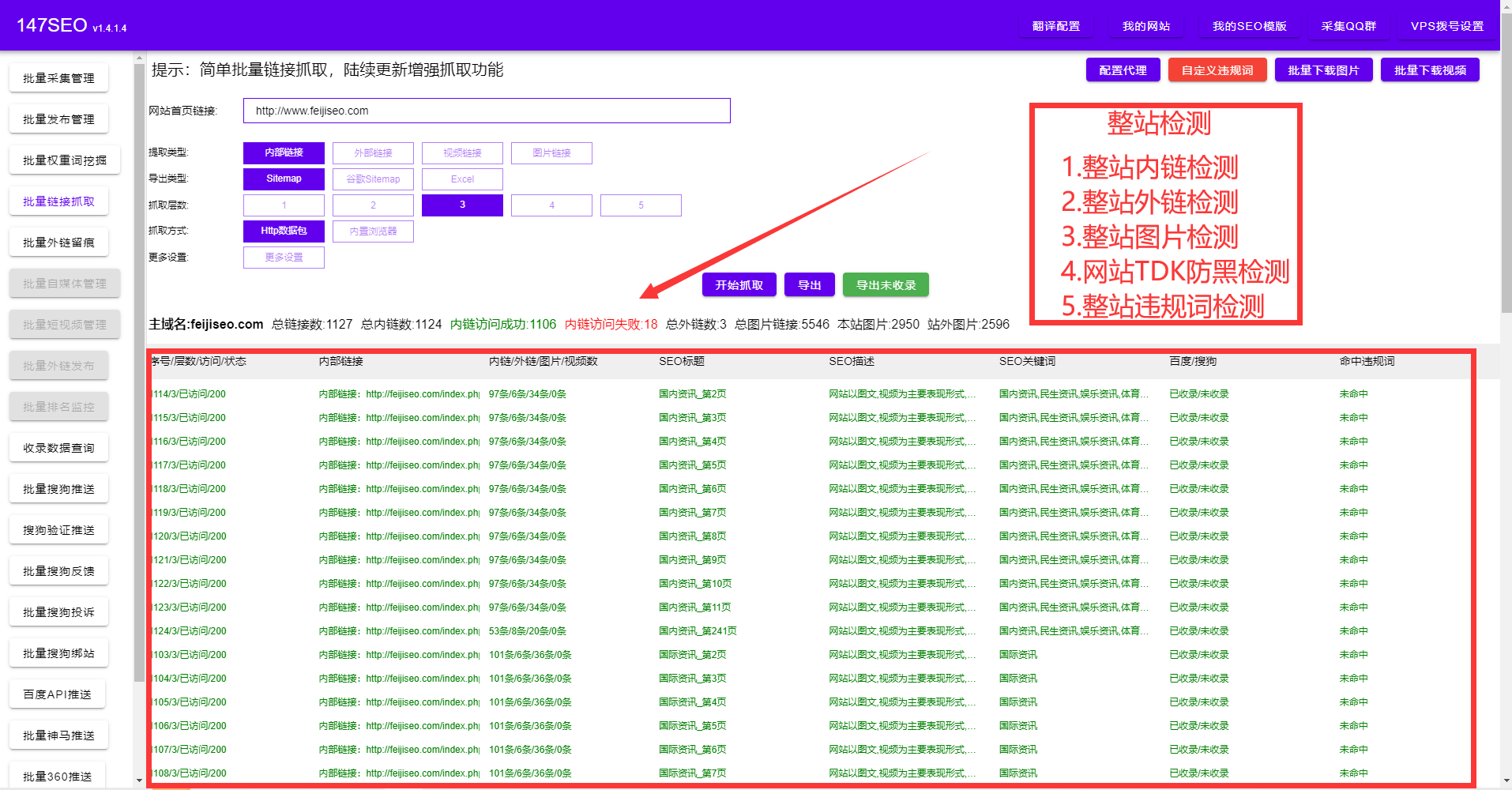
摘要:本文分享了作者在使用爬虫技术进行网页数据爬取时的心得和经验,揭示了爬虫技术对于探索无限信息世界的重要性。
在当今的信息时代,海量的数据正如洪流般汹涌而至。如何从这个汪洋大海中获取有价值的信息,成为了摆在我们面前的一道课题。而爬虫技术的出现,给我们提供了一种全新的、高效的方法来获取和利用这些数据。在这篇文章中,我将分享一下自己在使用爬虫技术进行网页数据爬取的心得和经验。

首先,要说到爬虫技术的重要性。在过去,我们获取信息的主要途径是通过搜索引擎或者浏览各种网页手动提取。这种方式不仅效率低下,而且容易出现遗漏或者误判的情况。而通过使用爬虫技术,我们可以自动化地从网页上抓取需要的数据,不仅速度快,而且准确度更高。这对于研究者、分析师等需要大量数据支撑的人群来说是非常有价值的。
其次,谈谈爬虫技术的应用场景。爬虫技术可以广泛应用于各个领域,如舆情监测、商品价格监控、yi学研究等。以舆情监测为例,通过爬取各大新闻媒体网站、社交媒体等pingtai的数据,我们可以及时了解到公众对于某个话题的舆情动态,对于政府和企业的舆情管理、市场调研等都有着重要的意义。在yi学研究方面,爬虫技术可以帮助我们从各大yi学数据库中获取bing例数据、论文数据等,为科学家和yi生提供更多的参考和依据。
接下来,我将分享一下自己在使用爬虫技术进行网页数据爬取时的几点心得和经验。

首先,要明确自己的数据需求。在进行网页数据爬取之前,我们需要明确自己需要获取的数据类型、数据量以及对数据的处理和分析需求。这有助于我们在制定爬虫策略、选择爬虫工具和优化爬取效率时有所侧重。
其次,合理设置爬虫的爬取频率和深度。过于频繁的爬取可能会对目标网站的正常运行造成影响,甚至会被网站封禁。因此,合理设置爬虫的爬取频率,避免造成不必要的麻烦。同时,根据自己的需求和目标网站的结构,合理设置爬虫的爬取深度,以避免爬取到无关数据或者过度深入到无效链接。
最后,要关注网站的反爬措施。为了保护网站的数据安全,很多网站会采取一些反爬虫的措施。在进行数据爬取时,我们需要时刻关注目标网站的反爬机制,避免被封禁或者被误判为恶意行为。我们可以通过模拟人工访问,设置合理的请求头、代理等方式来规避这些反爬措施。

通过以上的经验和心得,我成功地获取了大量的网页数据,为我的研究工作提供了重要的支撑。爬虫技术的出现让我们的信息获取更加高效、准确,也更加方便。在掌握了爬虫技术的同时,我们也要遵循相关的法律法规和道德规范,合法、合规地使用这项技术。
爬虫技术为我们打开了探索无限信息世界的大门。让我们一起拥抱这项技术,探索更广阔的数据世界,为科学研究、商业分析等领域带来更多的机遇和突破!