摘要:本文将教你如何使用网页抓取工具获取网络上的数据,从而实现数据采集与挖掘的目标。通过详细的步骤和实例,帮助你从初学者逐渐成为抓取网页数据的专家。
在信息时代,数据被称为新的石油,而获取和分析数据的能力已成为企业和个人的竞争力之一。无论你是想分析市场趋势、获取竞争对手的信息,还是进行学术研究,抓取网页数据都是一项必备的技能。本文将教你如何使用各种工具和技巧,从而成为抓取网页数据的专家。

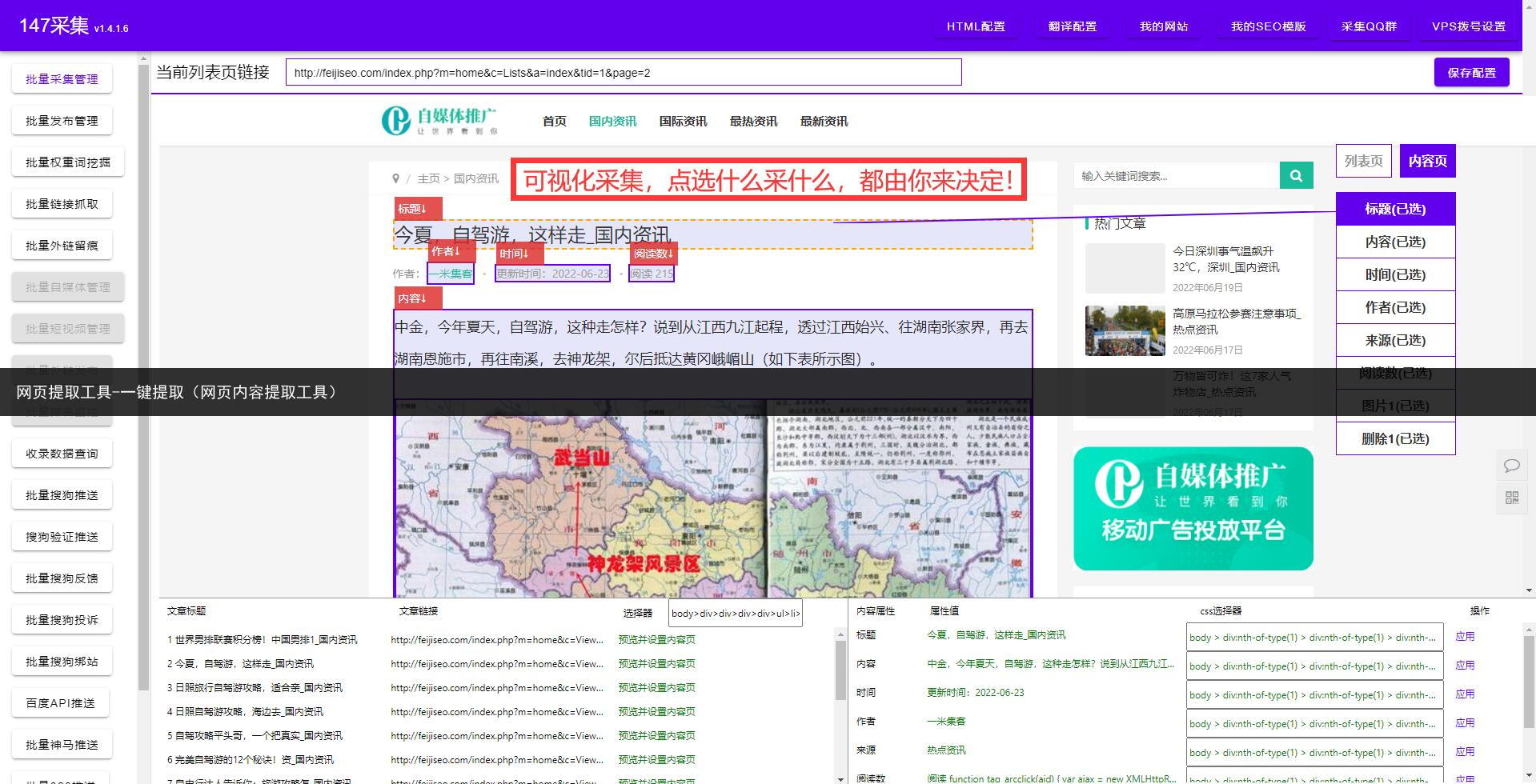
第一步是了解基本概念。抓取网页数据,简单来说,就是通过模拟浏览器行为,访问网页并提取感兴趣的数据。常见的数据格式有HTML、XML和JSON等,你需要根据具体情况选择合适的数据格式进行处理。
第二步是选择合适的抓取工具。市面上有很多强大的抓取工具,如Python的BeautifulSoup库、Scrapy框架、Node.js的Cheerio模块等。这些工具提供了丰富的功能和灵活的配置选项,可以帮助你快速高效地抓取网页数据。
第三步是分析网页结构。在抓取网页数据之前,你需要先了解网页的结构,包括HTML标签、元素的层次关系以及数据的位置。通过审查元素、查看源代码等方式,你可以快速定位到需要抓取的数据,并确定合适的抓取方法。

第四步是编写抓取程序。根据选择的工具和对网页结构的分析,你可以开始编写抓取程序。通常,你需要设置URL、请求头、请求参数等并发送HTTP请求,然后使用相应的解析方法提取数据。在编写程序时,注意处理可能出现的异常情况,如请求超时、网页不存在等。
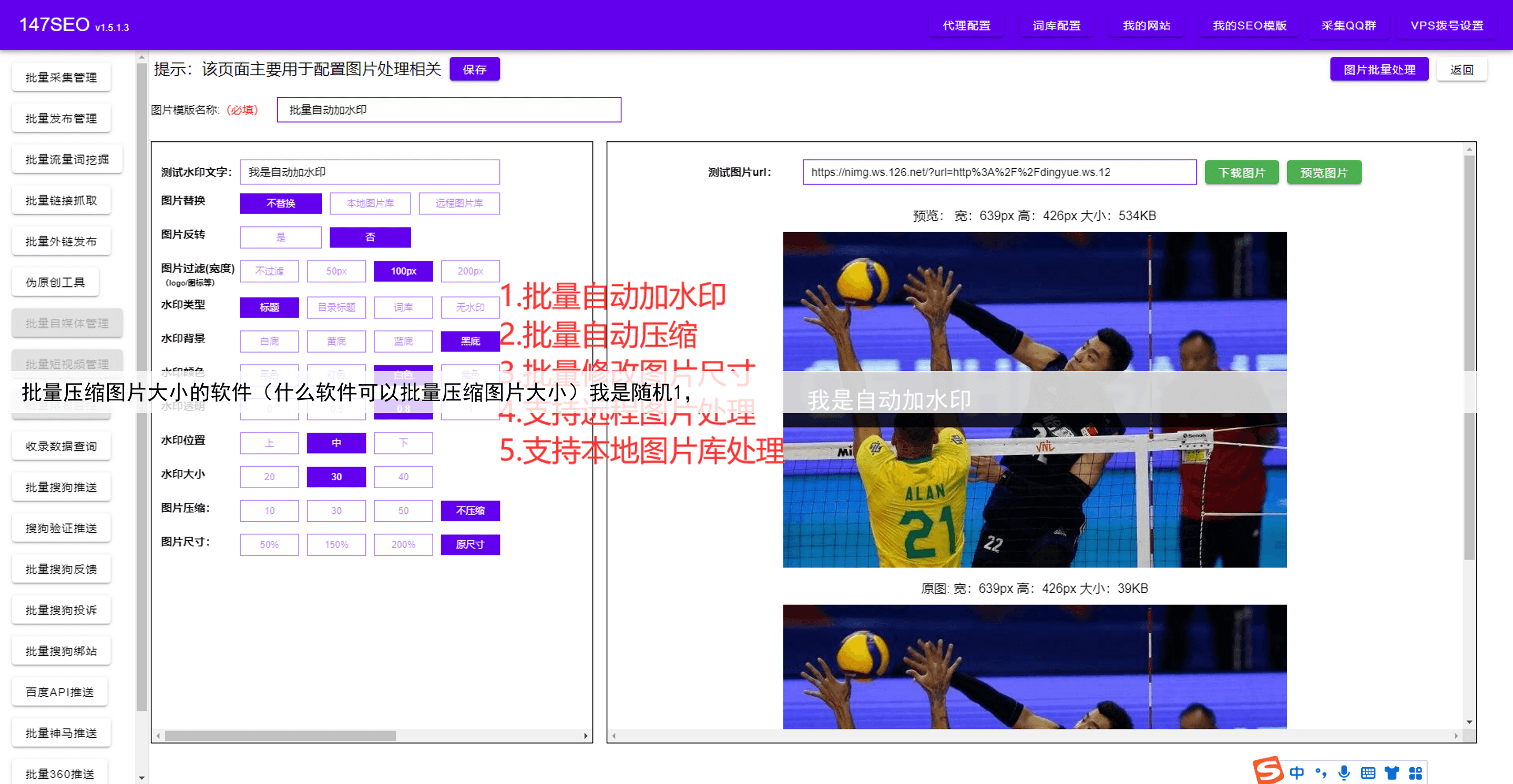
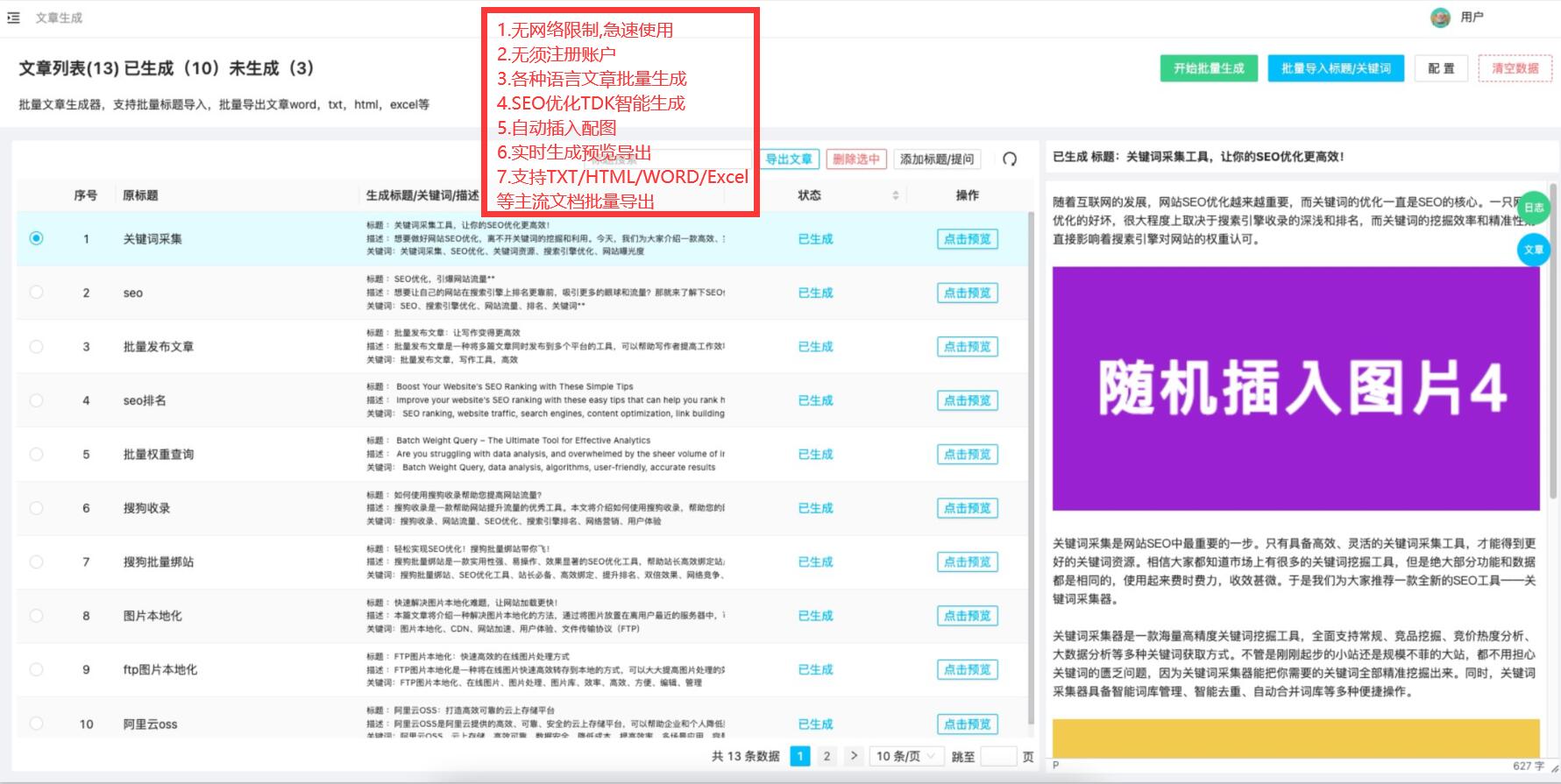
第五步是数据清洗和整理。抓取的数据通常需要经过清洗和整理,以便后续的分析和使用。你可以使用正则表达式、字符串处理方法或专业的数据清洗工具对数据进行清洗,并将数据保存为合适的格式,如CSV、Excel或数据库等。
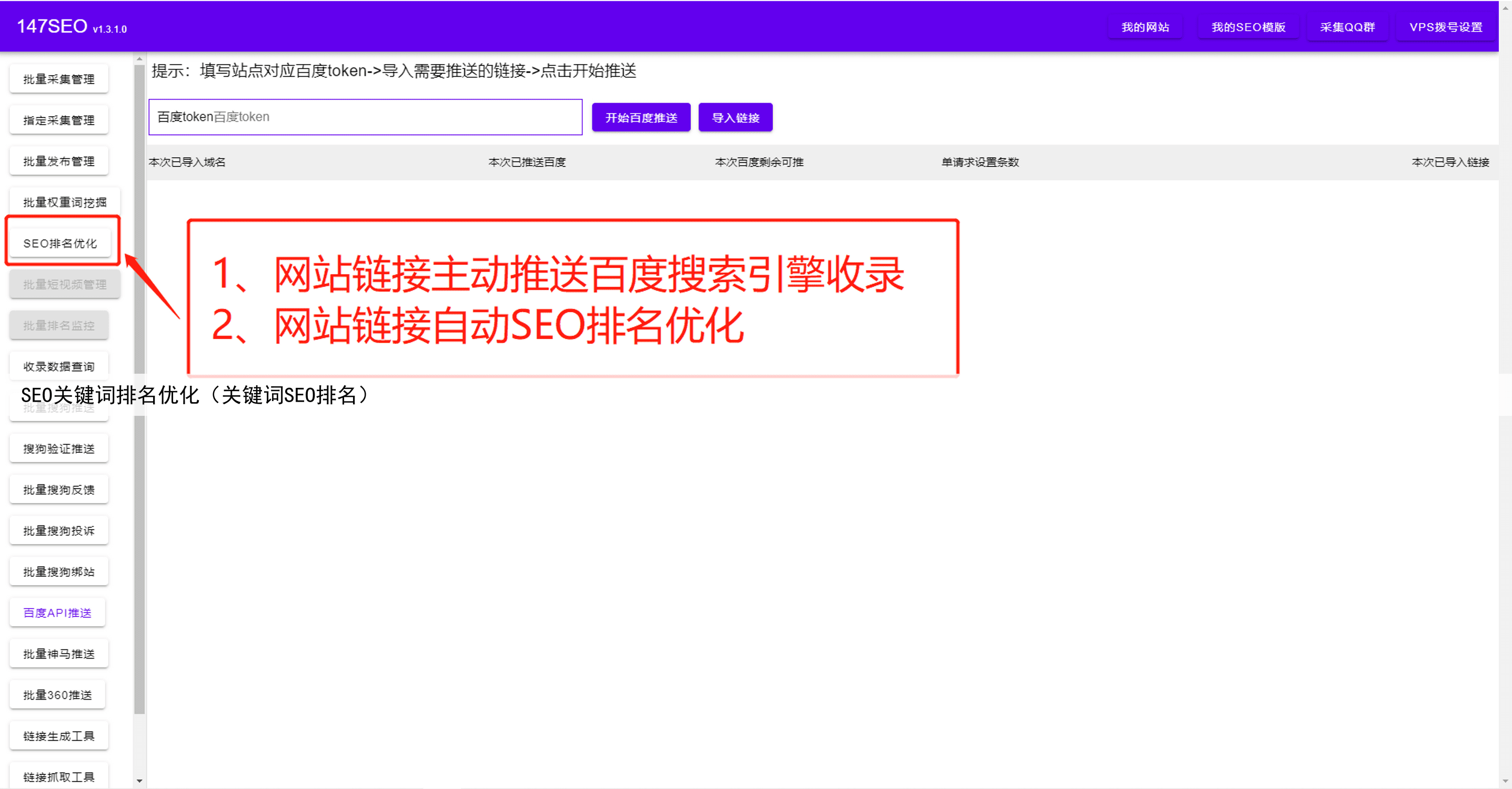
第六步是自动化和定时抓取。如果你需要定期获取网页数据,可以考虑使用自动化抓取工具,并设置定时任务。这样,你就不需要每次手动运行程序,而是可以自动获取最新的数据。

第七步是遵守法律和道德规范。在抓取网页数据时,我们需要遵守相关的法律和道德规范。尊重网站的所有权和使用规则,避免对网站造成不必要的负担,并遵守隐私保护的原则。
通过以上步骤的学习和实践,你可以成为一名抓取网页数据的专家。抓取网页数据是一项技术活,需要不断学习和实践,只有不断提升自己的能力,才能在日益竞争的数据时代中立于不败之地。希望本文能帮助你掌握抓取网页数据的关键技能,实现自己的目标和梦想!