摘要:本文将介绍通用爬虫抓取网页的流程,以及它在数据挖掘中的应用。
通用爬虫是一种用于抓取互联网上的各种网页信息的工具。它能够自动化地浏览网页并提取所需的数据,为数据挖掘和分析提供了基础。本文将介绍通用爬虫抓取网页的流程,并探讨它在数据挖掘中的各种应用。

通用爬虫抓取网页的流程一般分为以下几个步骤:
1.确定目标:在开始抓取之前,首先需要确定抓取的目标。这可能包括指定要抓取的网页、抓取的数据类型以及抓取的深度等。
2.发送HTTP请求:通用爬虫使用HTTP协议与网站进行通信。它将请求发送到目标网页的服务器,以获取响应内容。

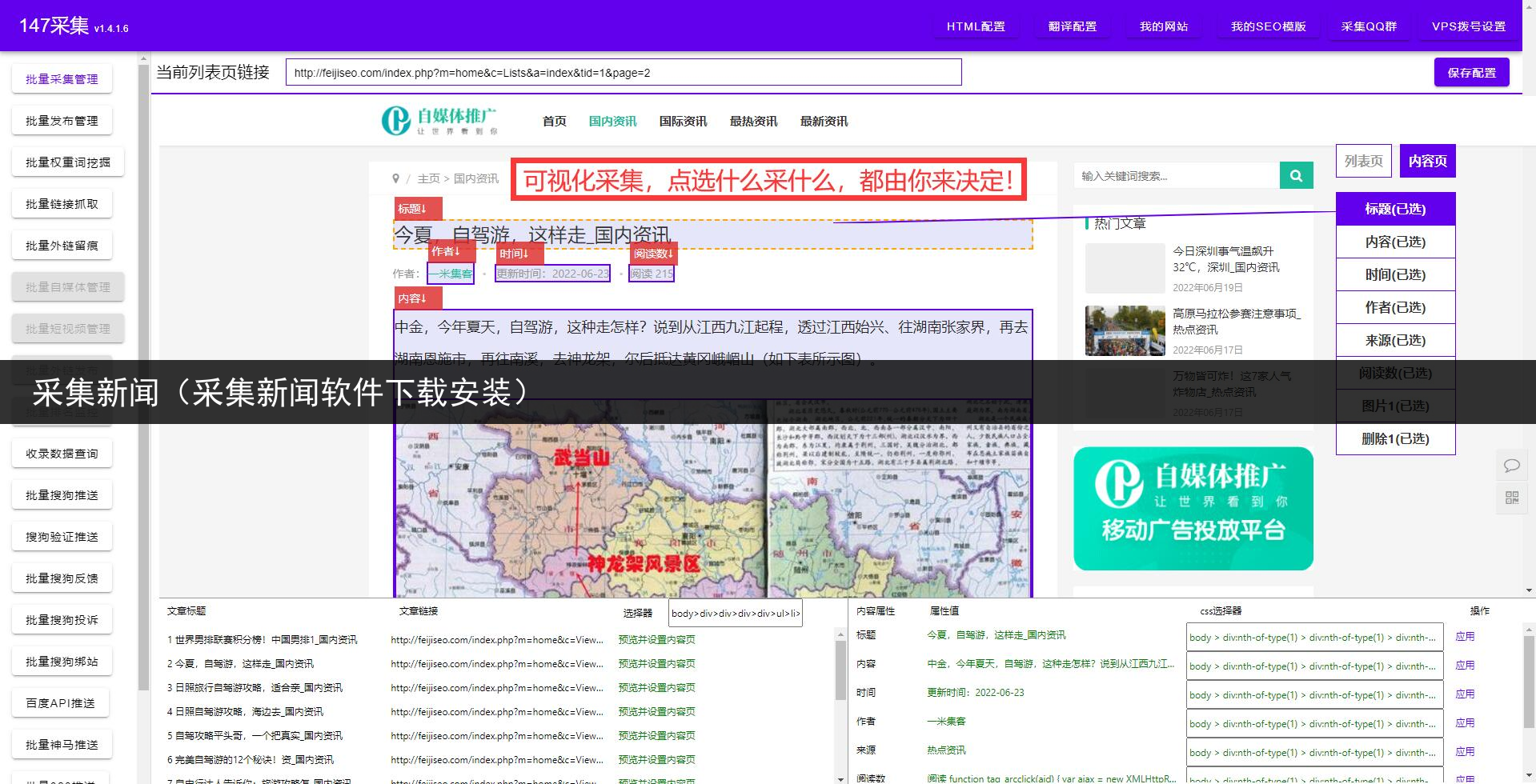
3.解析HTML:获取响应后,通用爬虫需要解析返回的HTML内容,以提取所需信息。解析可以使用各种技术如正则表达式、XPath或CSS选择器等。
4.提取数据:根据需求,通用爬虫将从解析后的HTML文档中提取出所需的数据。这可能包括文本、图片、链接或其他结构化数据。
5.存储和处理数据:抓取到的数据通常需要进行存储和处理。可以使用数据库或文本文件等方式,将数据持久化保存,并进行后续的数据挖掘和分析。

通用爬虫在数据挖掘中具有广泛的应用。以下是一些常见的应用场景:
1.搜索引擎优化(SEO):通用爬虫可用于抓取网站,并通过分析网页内容和结构,提供搜索引擎优化的建议。这有助于改善网站在搜索引擎结果中的排名。
2.市场调研和竞争分析:通过抓取竞争对手的网页信息,可以了解其产品、价格和营销策略等。这为企业制定市场策略提供有价值的参考。

3.新闻和媒体监测:通过抓取新闻网站和社交媒体pingtai的信息,可及时获取最新的新闻和舆情动态,帮助企业进行舆情监测和危机公关。
4.数据分析和建模:通过抓取大量的网页数据,可以进行数据分析和建模,以发现隐藏在数据背后的规律和趋势。这对于商业决策和市场预测有重要意义。
综上所述,通用爬虫在抓取网页和数据挖掘中起着重要的作用。了解其流程和应用场景,可以帮助我们更好地利用这一工具。希望本文能为读者提供关于通用爬虫的基本认识,并启发大家在数据挖掘领域的探索和创新。