摘要:本文介绍了爬虫在如何处理数据的过程中的重要性和一些常见的数据处理方法。
爬虫如何处理数据

在互联网时代,数据被认为是最为宝贵的ZY之一。大量的数据存在于网络中,众多企业和机构需要利用这些数据来进行业务分析和决策。而爬虫作为一种自动化的技术工具,扮演着重要的角色,能够有效地从互联网中抓取和提取数据。那么,爬虫如何处理数据呢?
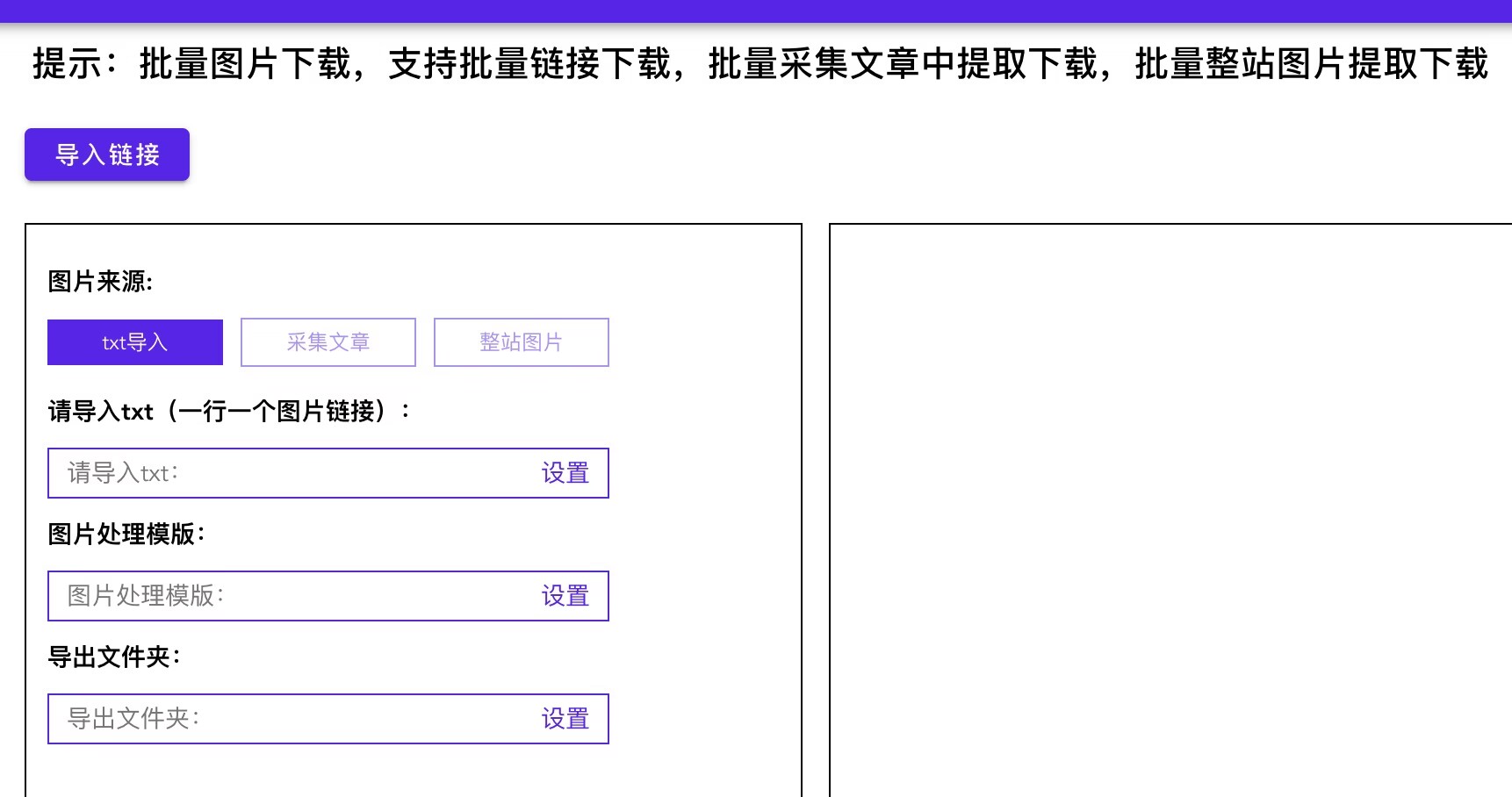
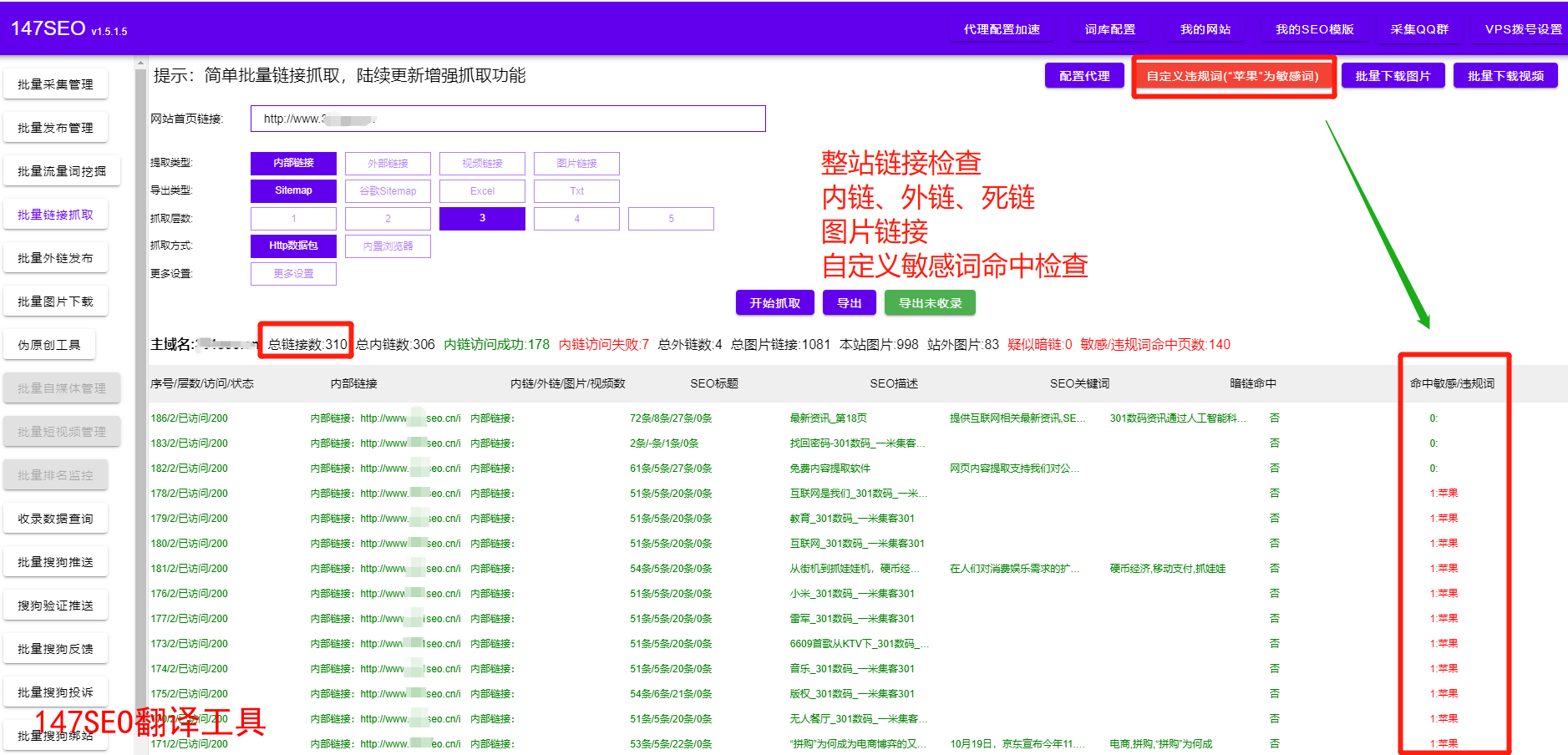
首先,爬虫需要确定所要抓取的数据源。不同的网站和应用提供不同的数据结构和接口,爬虫需要根据具体情况编写抓取规则和代码。常见的数据抓取方式包括网页爬取、API调用和数据库查询等。通过使用Python、Java等编程语言,爬虫可以轻松地从网页中提取所需数据。
其次,爬虫需要处理数据的格式和结构。爬取的数据通常以HTML、XML或JSON等格式存在,爬虫需要根据需求进行解析和处理。常见的数据处理方法包括数据清洗、数据转换和数据过滤等。数据清洗可以去除重复、无效或冗余的数据,提高数据的质量和准确性;数据转换可以将数据转化为特定的格式,方便后续的分析和处理;数据过滤可以根据条件筛选出符合特定要求的数据。

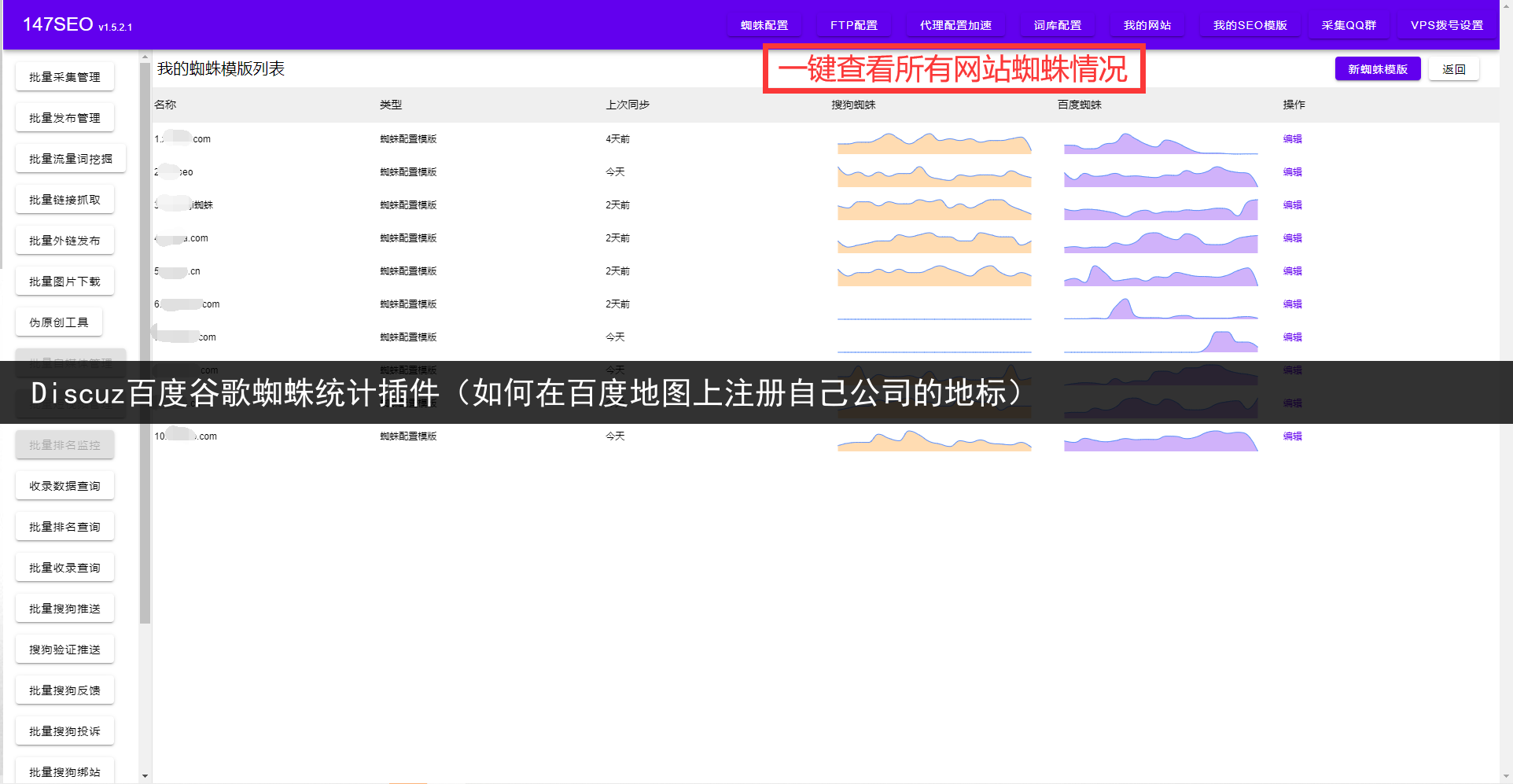
另外,爬虫还需要处理数据的存储和管理。爬虫可以将抓取到的数据保存到本地文件或数据库中,方便后续的访问和使用。对于大规模的数据抓取和处理,爬虫需要设计合理的数据存储结构和管理策略,以提高数据的访问效率和管理性能。
总的来说,爬虫在处理数据的过程中,需要确定数据源、处理数据格式和结构,以及存储和管理数据。通过合理的抓取规则和数据处理方法,爬虫可以高效地从互联网中提取和处理大量的有价值的数据。爬虫的发展也推动了数据分析和数据挖掘等领域的发展,为各行各业提供了更多的数据支持和决策参考。
关键词:爬虫、数据处理、网络爬虫、数据抓取