摘要:本文介绍如何使用Python爬虫技术创建全新数据库,并探讨数据抓取、分析和处理的实用方法。
在信息时代的今天,数据已经成为企业和个人决策的重要参考依据。而为了更好地管理和利用数据,创建一个高效的数据库至关重要。Python爬虫技术的出现为我们提供了一种强大的方式来抓取互联网上的数据,并将其存储在数据库中。本文将以Python爬虫技术为基础,介绍如何创建全新数据库,并探讨数据抓取、分析和处理的实用方法。

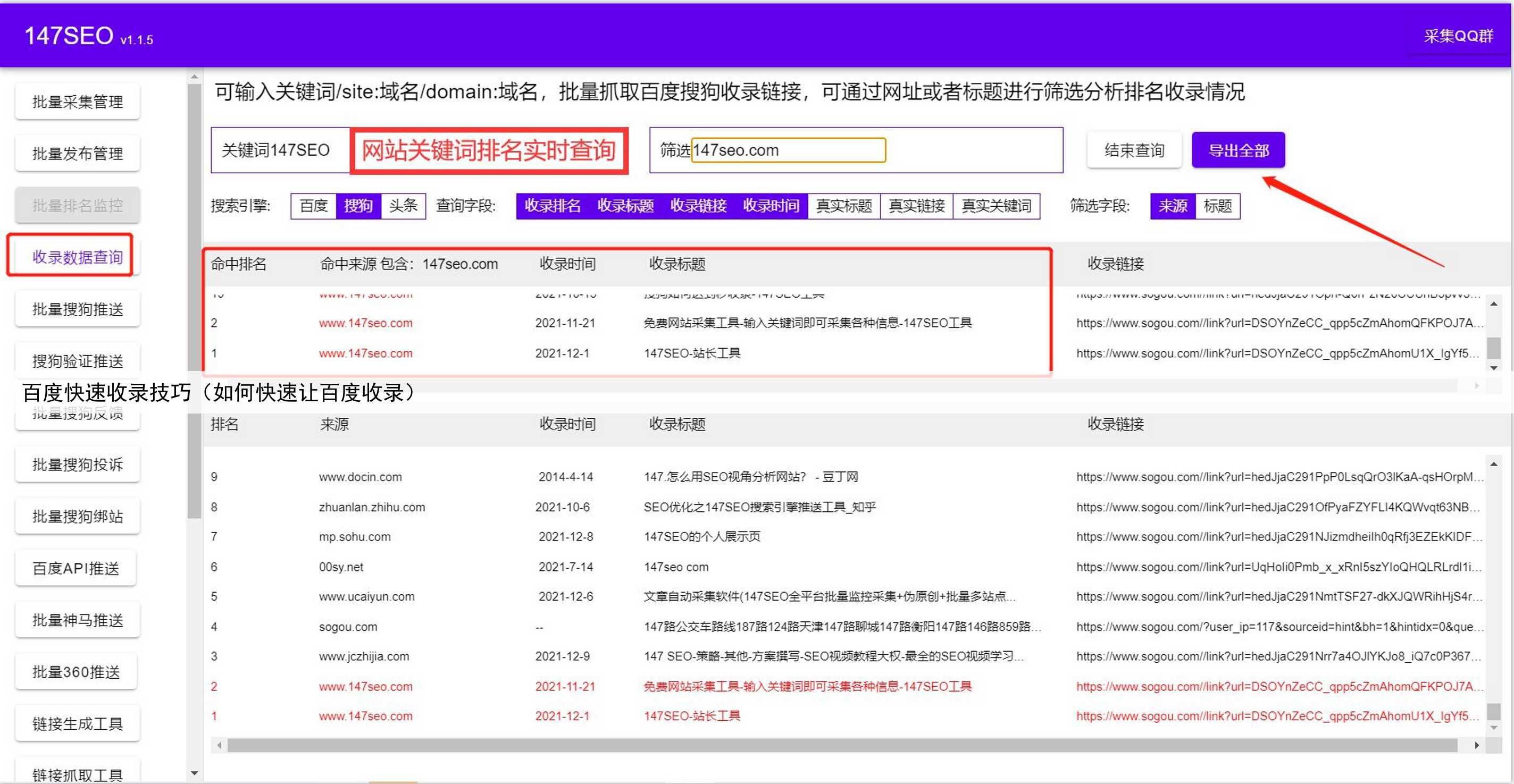
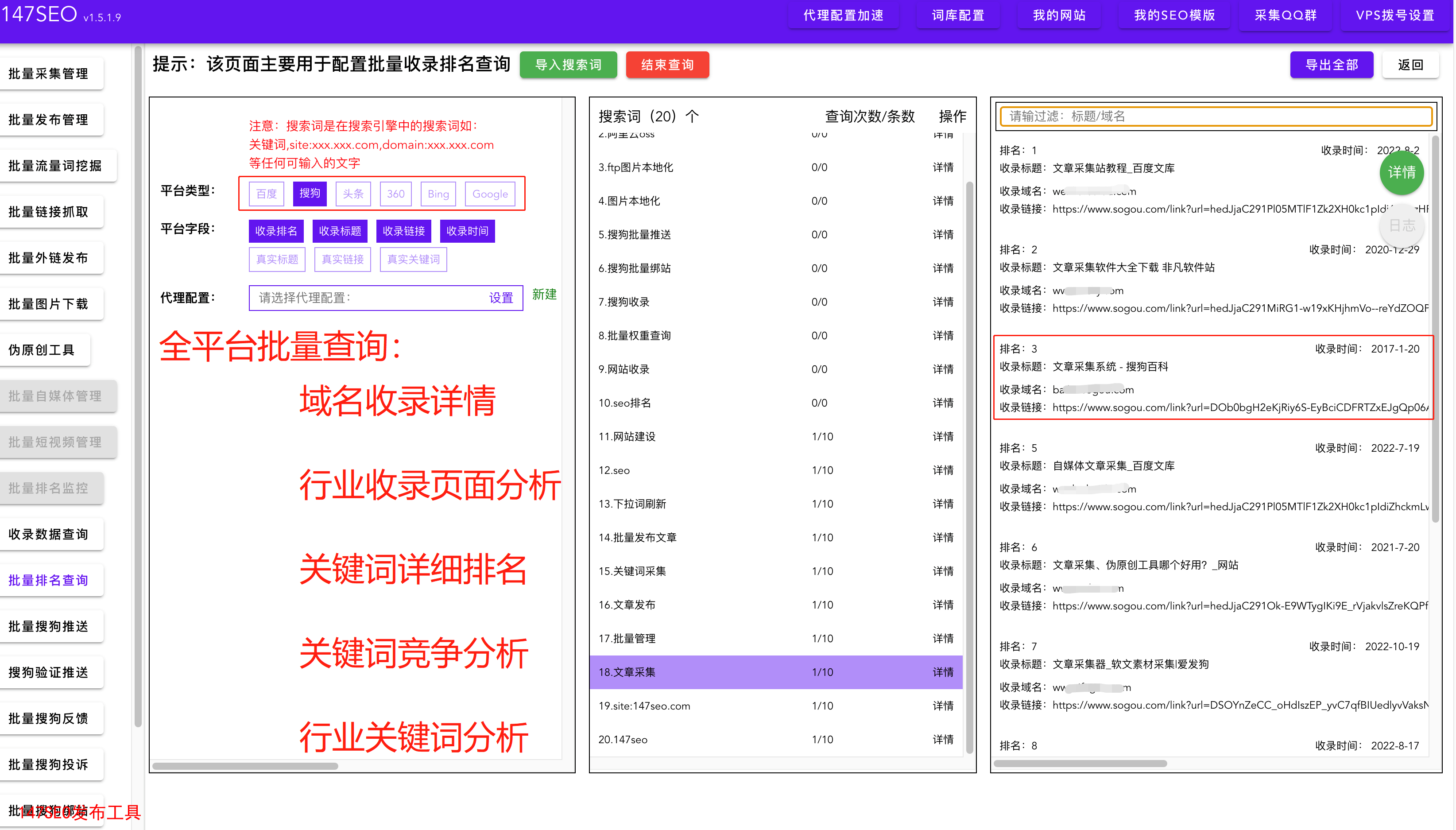
Python爬虫是一种自动化从网页中抓取数据的技术。它可以模拟浏览器的行为,访问指定的网页,提取目标数据,并将其存储为结构化的格式,如JSON或CSV。首先,我们需要使用Python爬虫技术抓取所需的数据。可以使用Python内置的urllib库或第三方库,如Requests和BeautifulSoup,来实现网页的访问和数据的抓取。通过分析网页的结构和标签,我们可以找到目标数据所在的位置,并使用相应的方法提取出来。
抓取到的数据通常需要经过一些预处理和清洗才能被存入数据库中。在数据分析和处理阶段,我们可以使用Python的各种数据分析库,如Pandas和NumPy,来对抓取到的数据进行处理和分析。这些库提供了丰富的功能和方法,能够帮助我们对数据进行清洗、过滤、转换和计算等操作。通过使用这些库,我们可以从抓取到的庞大数据中提取有用的信息,并将其存入数据库中。
在选择数据库时,我们需要根据自己的需求和数据特点来进行选择。流行的数据库包括MySQL、SQLite、MongoDB等。MySQL是一种关系型数据库,适用于结构化数据的存储和管理。SQLite是一种嵌入式数据库,适用于小型项目和个人使用。而MongoDB是一种NoSQL数据库,适用于非结构化和半结构化的数据存储。根据数据的特点和规模选择合适的数据库,可以有效地提高数据的存储和查询效率。

在创建数据库时,我们需要定义合适的表结构,并使用Python的数据库操作库,如MySQLdb、sqlite3或PyMongo,来执行数据库的创建、插入、更新和查询等操作。通过Python的数据库操作库,我们可以方便地连接数据库、执行SQL语句、提交事务和获取查询结果。同时,我们还可以借助ORM(对象关系映射)工具,如SQLAlchemy和DjangoORM,来简化数据库操作,并提高代码的可维护性和可扩展性。
通过使用Python爬虫技术创建数据库,我们可以方便地获取和管理互联网上的各种海量数据。无论是进行市场调研、用户分析还是商业决策,都离不开对数据的抓取、分析和处理。Python爬虫技术的应用不仅提高了数据挖掘和分析的效率,也为我们带来了更多的商业机会。只要我们有足够的耐心和技术积累,就能够在海量的数据中挖掘出有价值的信息,并为企业和个人带来更多的收益。