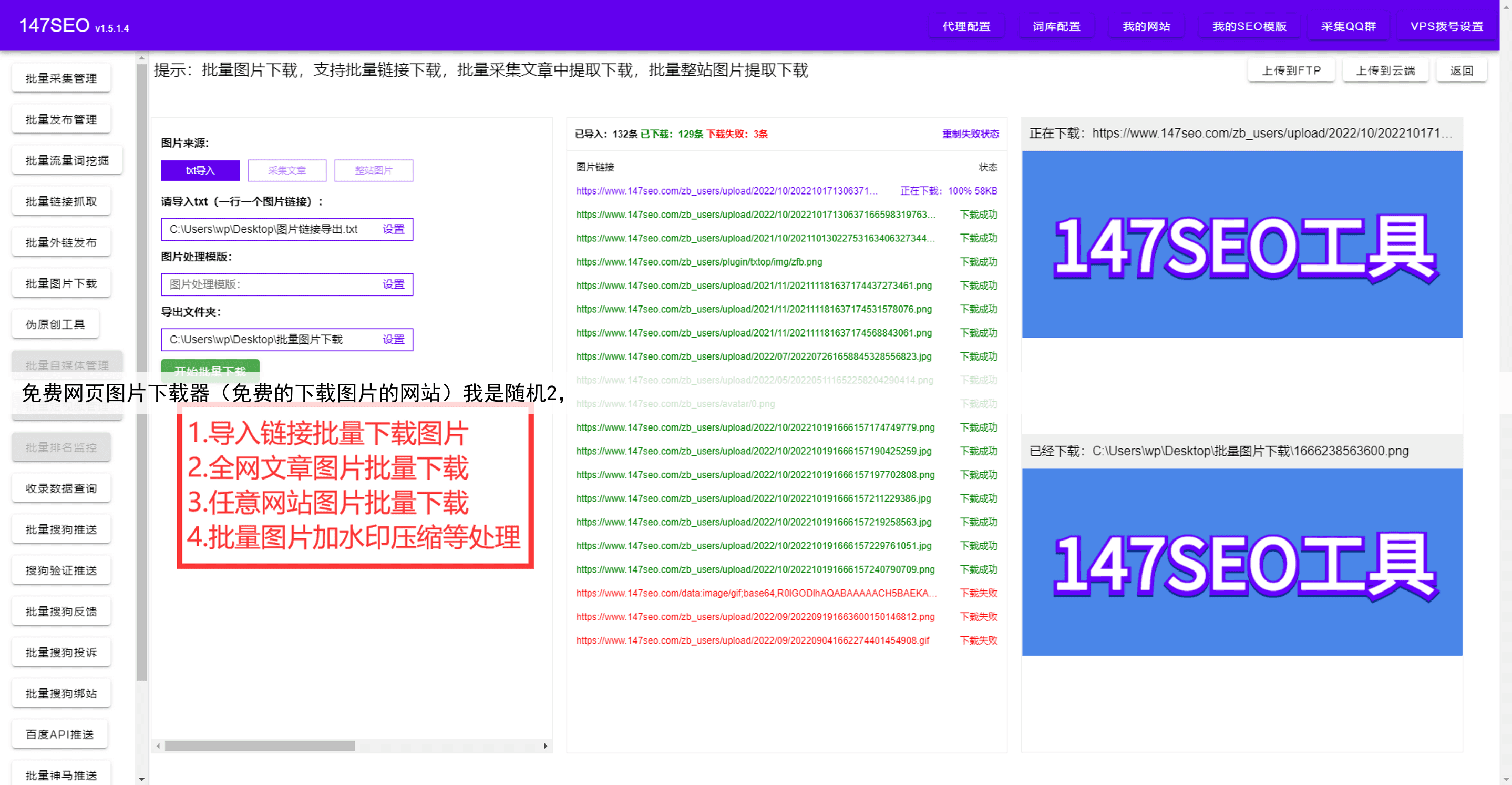
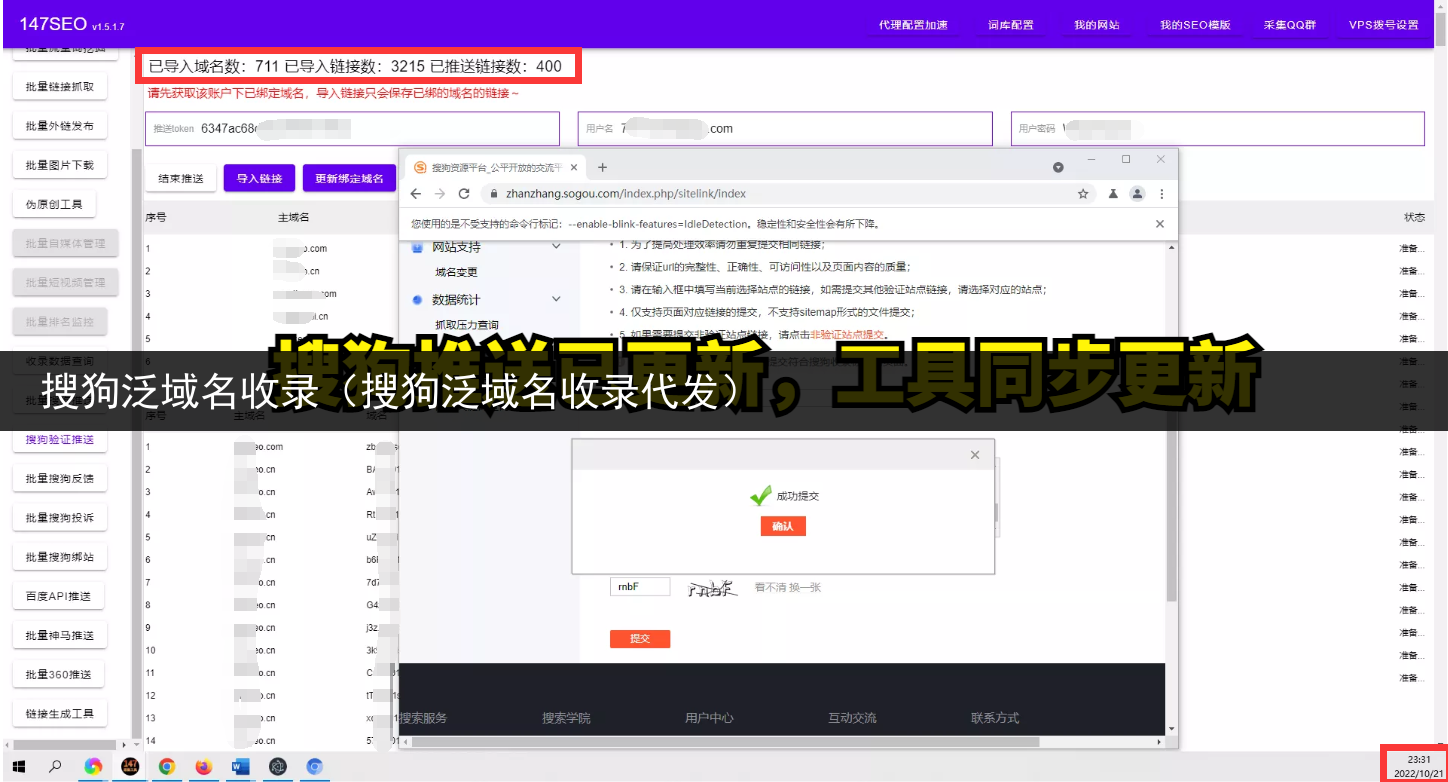
摘要:本文将介绍如何使用爬虫将网页数据高效保存到文件,并提供符合软文风格的标题和内容。
作为一名爬虫爱好者或从业者,我们经常需要将爬取到的网页数据保存下来,以便后续的分析、处理或展示。下面将分享一些高效的方法来保存爬虫数据,并附上符合软文风格的标题和内容,希望对大家有所帮助。
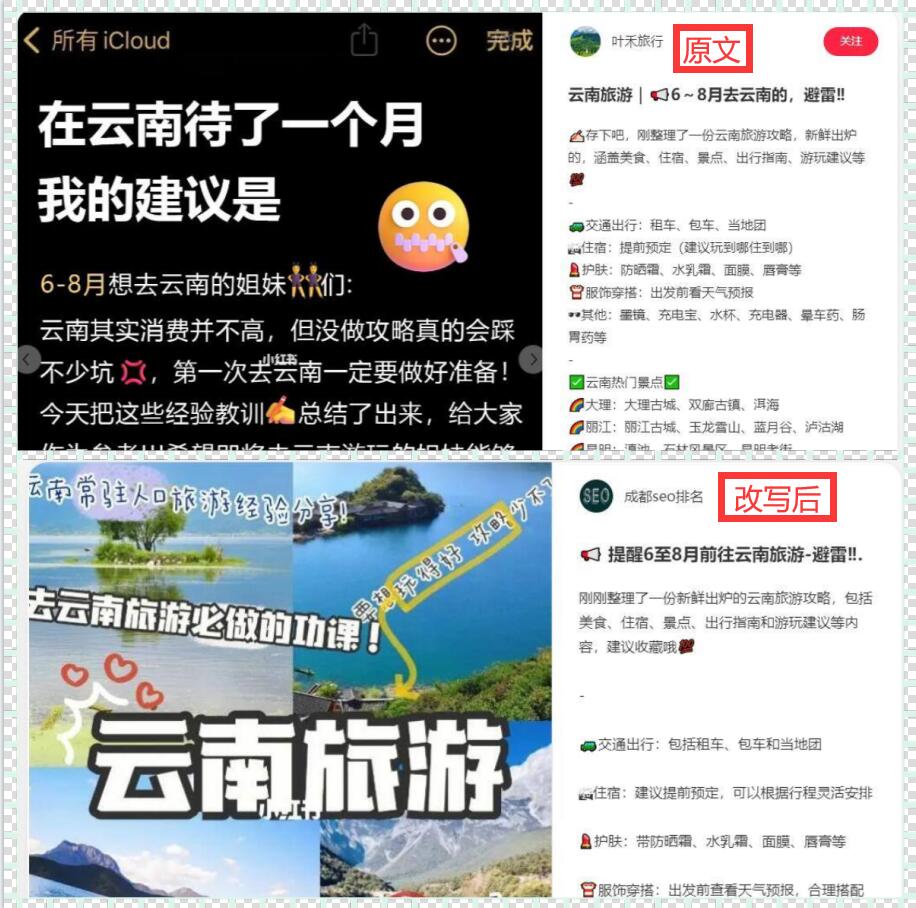
1.存储为JSON文件
JSON(JavaScriptObjectNotation)是一种轻量级的数据交换格式,常用于保存结构化的数据。我们可以将爬虫得到的数据以JSON格式保存到文件中,以便后续的读取和处理。使用Python中的json模块可以方便地实现JSON格式的序列化和反序列化。
2.创建结构化数据
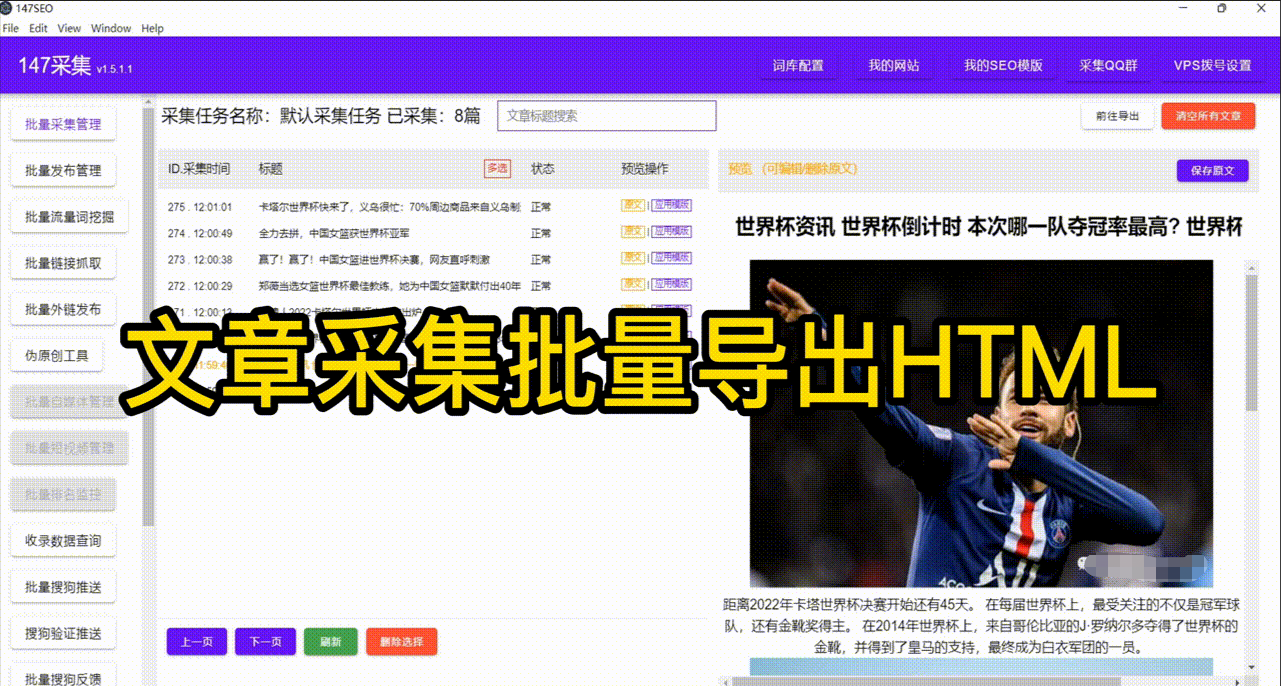
保存爬虫数据时,我们应该尽量使数据结构化,以方便后续的分析和处理。例如,可以使用字典嵌套的方式来表示不同字段的数据。对于每个爬取到的网页,可以将其标题、链接、正文等字段作为一个字典的键值对存储起来。
3.多文件存储
当需要保存大量的爬虫数据时,可以考虑将数据分为多个文件存储,以便提高读写效率和减少单个文件的大小。可以根据不同的网站或主题来划分存储文件,或者按照时间进行分割。

4.命名规则
为了方便识别和管理保存的数据文件,建议使用有意义的命名规则。可以根据爬取的网站名称、主题、时间等信息来构建文件名。例如,可以使用网站域名加上时间戳的方式来命名文件,以确保文件名的唯一性。
5.文件路径

保存数据文件时,需要选择合适的文件路径来存储。建议将数据文件存储在独立的文件夹中,以避免混杂在其他文件中。可以根据需要来创建不同的文件夹,以便对数据文件进行分类和管理。同时,还需要确保文件路径的可访问性,以便后续的读取和处理。
6.错误处理
在保存爬虫数据时,我们需要考虑到可能出现的错误情况,并进行相应的处理。例如,如果出现写文件失败的情况,可以选择重试、忽略或记录错误信息。为了确保数据的完整性和一致性,建议在保存数据之前进行必要的数据校验。
综上所述,将爬虫数据保存到文件是一个关键的环节,对于后续的数据分析和处理至关重要。希望通过本文的介绍,能够帮助大家掌握高效保存爬虫数据的技巧,并在保存文件时遵循软文风格的要求。