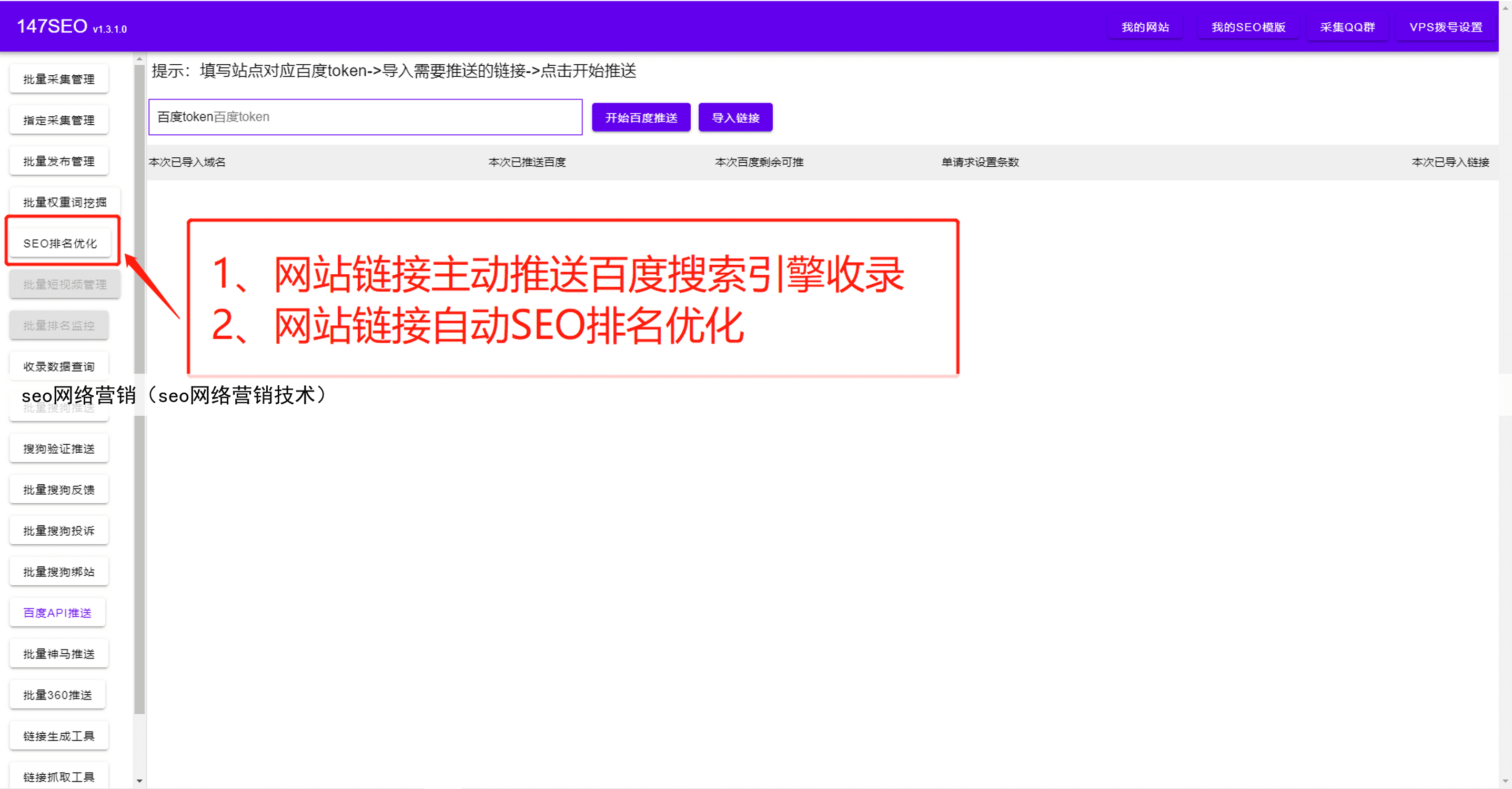
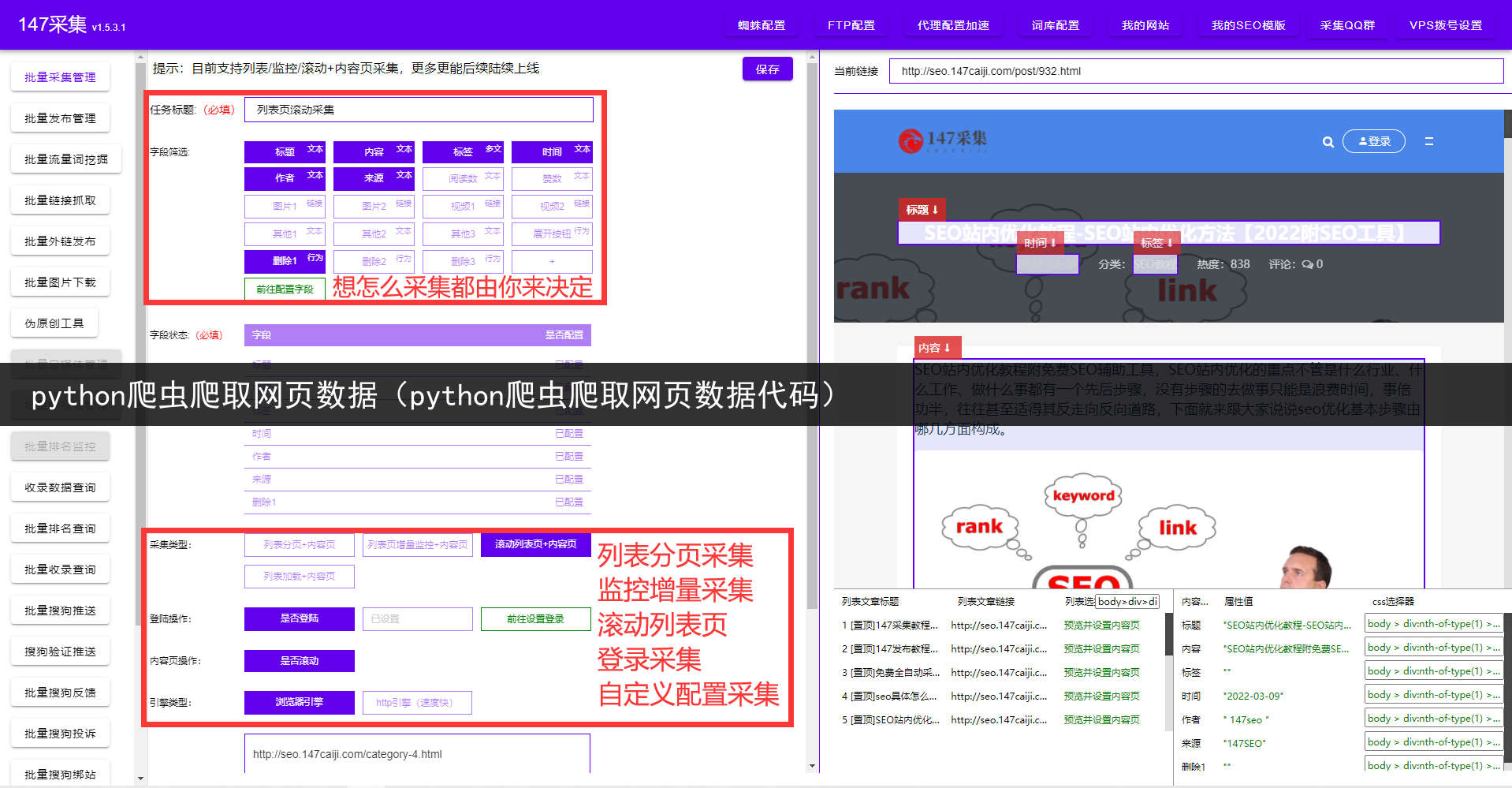
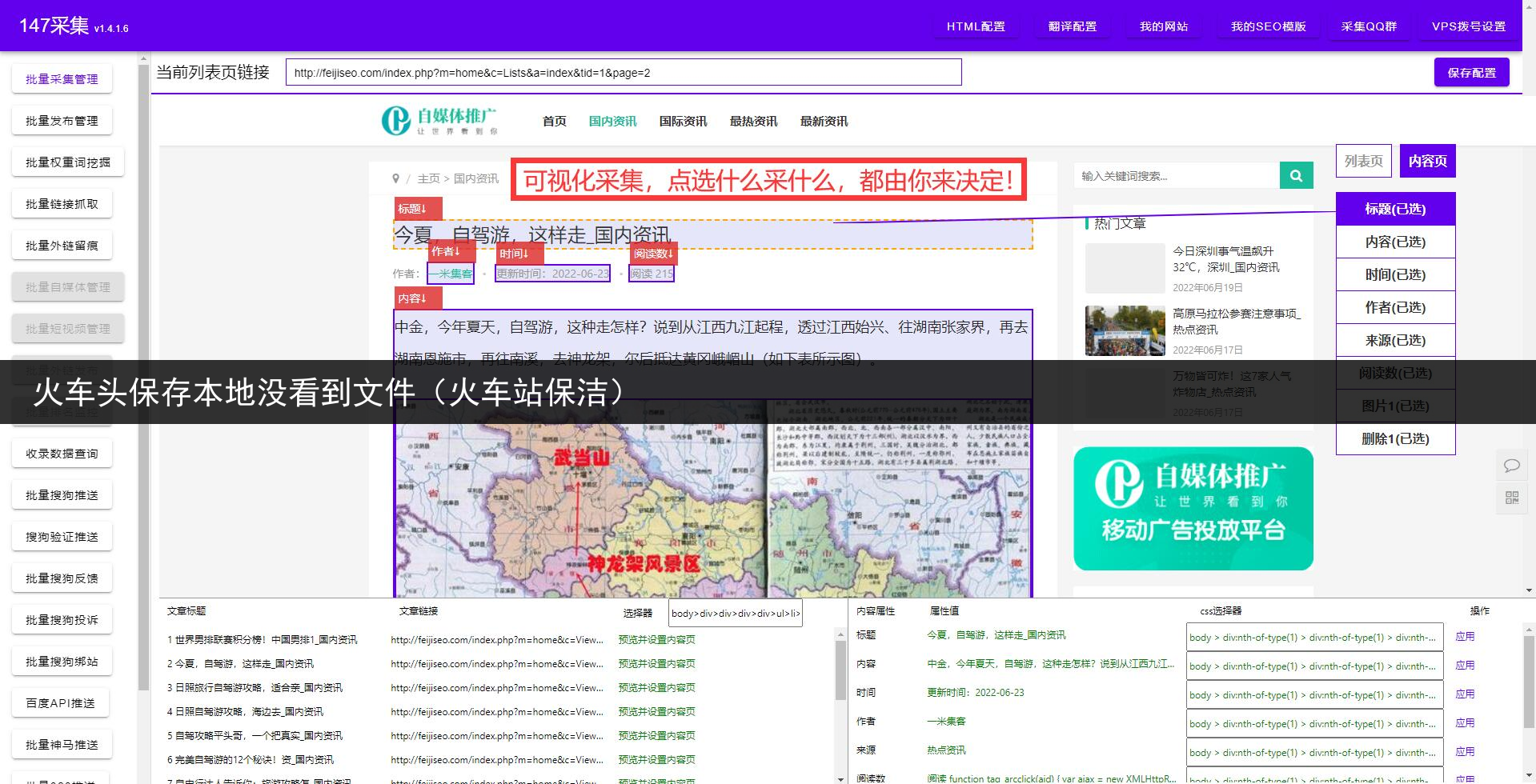
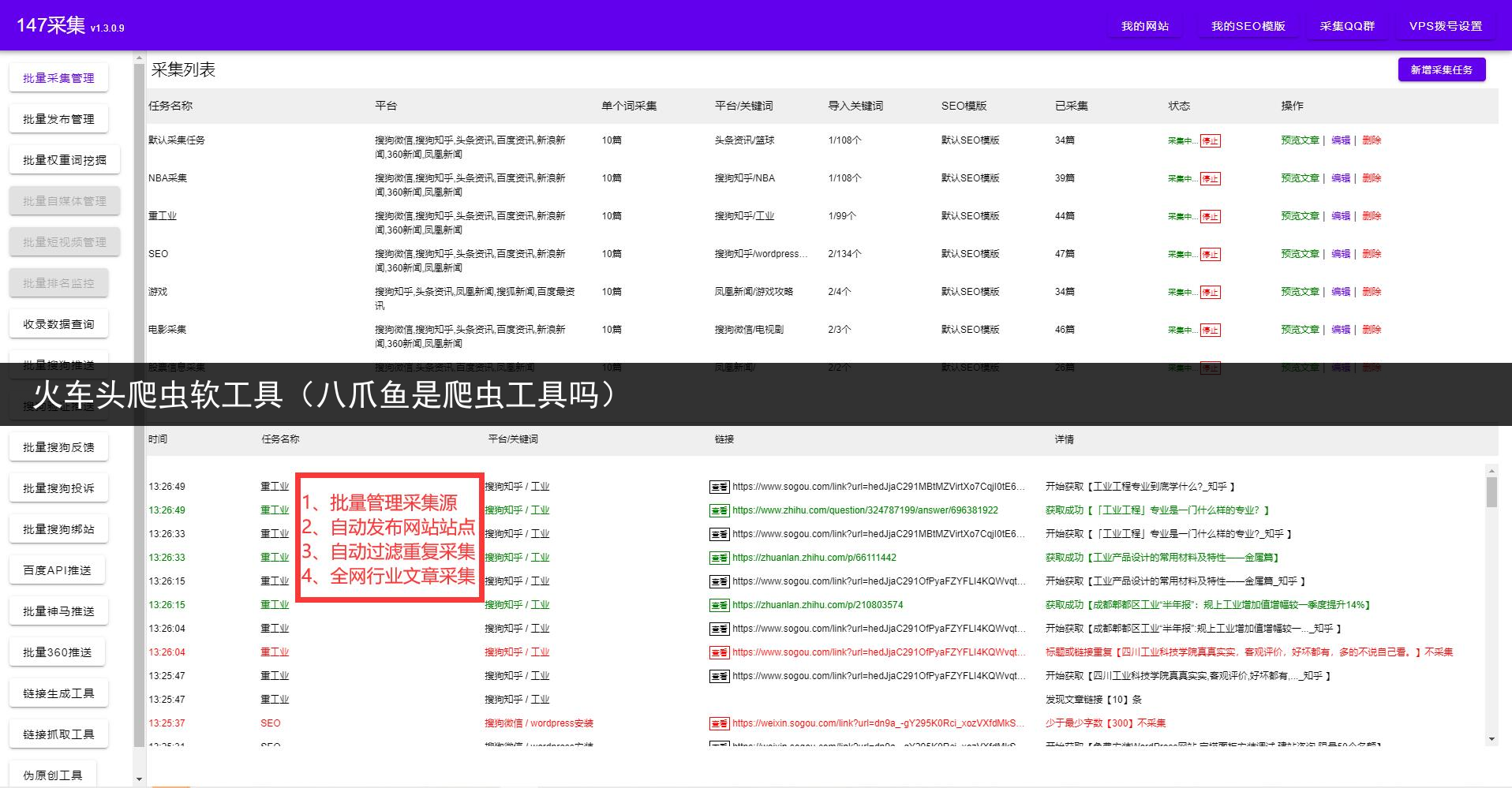
摘要:火车头爬虫软件,零基础小白的话可以多参考图片。在使用火车头爬虫软件之前你需要有基础的HTML知识,必须能够看懂网页源码和网页结构。不然完全无法上手!如果要用到web自动发布或数据库自动发布,则需要对自己网站系统及数据存储结构要非常了解。否则将会无法使用。如果这方面你都不太了解,或者没有那么多的时间去学习。那么可以使用更简单的免费爬虫软件详细如图,只需要鼠标点几下就可以轻松拿到自己想要的数
目录:
1.火车头爬虫和八爪鱼
2.八爪鱼爬虫工具可以干嘛
3.八爪鱼爬取器
4.八爪鱼爬虫怎么用
5.八爪鱼爬虫软件教程
6.八爪鱼爬虫软件下载
7.八爪鱼网络爬虫工具
8.火车头采集器和八爪鱼
9.八爪鱼爬虫软件是干什么用的
10.类似于八爪鱼的爬虫软件
1.火车头爬虫和八爪鱼
火车头爬虫软件,零基础小白的话可以多参考图片在使用火车头爬虫软件之前你需要有基础的HTML知识,必须能够看懂网页源码和网页结构不然完全无法上手!如果要用到web自动发布或数据库自动发布,则需要对自己网站系统及数据存储结构要非常了解。
2.八爪鱼爬虫工具可以干嘛
否则将会无法使用如果这方面你都不太了解,或者没有那么多的时间去学习那么可以使用更简单的免费爬虫软件详细如图,只需要鼠标点几下就可以轻松拿到自己想要的数据!!!!同时也配备了全自动发布
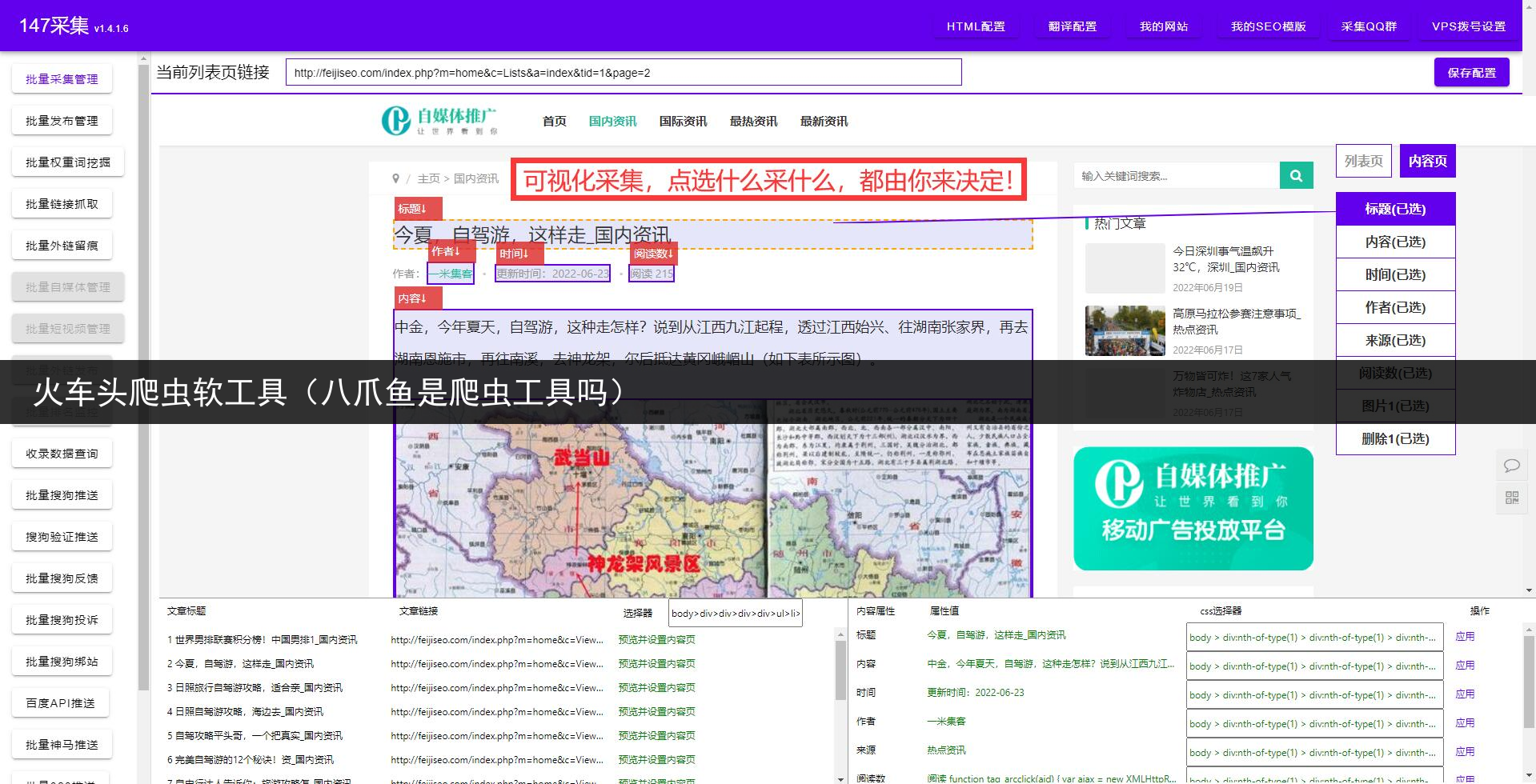
3.八爪鱼爬取器
火车头爬虫软件标签编辑对数据内容标签进行编辑定义,数据的获取方式有A).从源码中获取数据B).生成固定格式的数据C).已有标签组合
4.八爪鱼爬虫怎么用
A).从源码中获取数据:可精确地设置标签的来源是从默认页的源码、返回头信息和网页地址中,或者是分页、循环分块、多页中其数据提取方式包括:A.a).前后截取A.b).正则提取A.c).正文提取A.d).Xpath提取。
5.八爪鱼爬虫软件教程
A.e).JSON 提取B).生成固定格式的数据:可生成固定的字符串、系统时间、随机字符串、随机数字、系统时间戳、随机抽取信息C).已有标签组合:可通过组合已有的标签,来生成新的标签内容

6.八爪鱼爬虫软件下载
A.a).前后截取通过设置开始字符串和结束字符串,来获取中间的字符,可以在开始和结束字符串中设置通配符(*)A.b).正则提取支持两种正则,一个纯正则,一个参数正则先介绍纯正则,举个例子,如:前字符串 (?[\s\S]*?)后字符串,这个正则其实效果跟前后截取一样,。
7.八爪鱼网络爬虫工具
如需要获取全部代码,则为^(?[\s\S]*?)$ ,此功能运用需有一定的正则基础关于参数正则,是通过参数组合,来生成内容比如说要匹配标题为“新用户注册”和作者“神秘嘉宾”,代码如下:。
8.火车头采集器和八爪鱼
新用户注册
9.八爪鱼爬虫软件是干什么用的
A.d).Xpath提取通过Xpath表达式来获取数据,比如//div[@id=’content’],就是获取id为content的div可指定要获取html节点的属性,比如 Innerhtml、Outerhtml、Innertext、Href属性。
10.类似于八爪鱼的爬虫软件
(注意:这种有一定的局限性,对于部分html标签不规范的页面无法解析。)A.e).JSON提取

通过对JSON形式的数据格式化操作,写表达式来获取其节点数据。详细教程后续分解。